

Basis fashions ship spectacular out-of-the-box efficiency for common duties, however many organizations want fashions to devour their enterprise information. Mannequin customization helps you bridge the hole between general-purpose AI and your particular enterprise wants when constructing purposes that require domain-specific experience, implementing communication types, optimizing for specialised duties like code era, monetary reasoning, or guaranteeing compliance with business rules. The problem lies in how one can customise successfully. Conventional supervised fine-tuning delivers outcomes, however solely you probably have hundreds of rigorously labeled examples displaying not simply the proper last reply, but in addition the entire reasoning path to achieve it. For a lot of real-world purposes, particularly these duties the place a number of legitimate resolution paths exist, creating these detailed step-by-step demonstrations can typically be costly, time-consuming.
On this put up, we discover reinforcement fine-tuning (RFT) for Amazon Nova fashions, which generally is a highly effective customization approach that learns by way of analysis relatively than imitation. We’ll cowl how RFT works, when to make use of it versus supervised fine-tuning, real-world purposes from code era to customer support, and implementation choices starting from totally managed Amazon Bedrock to multi-turn agentic workflows with Nova Forge. You’ll additionally study sensible steerage on knowledge preparation, reward operate design, and greatest practices for attaining optimum outcomes.
A brand new paradigm: Studying by analysis relatively than imitation
What in the event you may train a automobile to not solely study all of the paths on a map, however to additionally discover ways to navigate if a improper flip is taken? That’s the core concept behind reinforcement fine-tuning (RFT), a mannequin customization approach we’re excited to convey to Amazon Nova fashions. RFT shifts the paradigm from studying by imitation to studying by analysis. As an alternative of offering hundreds of labeled examples, you present prompts and outline what makes a last reply right by way of take a look at circumstances, verifiable outcomes, or high quality standards. The mannequin then learns to optimize these standards by way of iterative suggestions, discovering its personal path to right options.
RFT helps mannequin customization for code era and math reasoning by verifying outputs routinely, eliminating the necessity for offering detailed step-by-step reasoning. We made RFT accessible throughout our AI providers to fulfill you wherever you’re in your AI journey: begin easy with the fully-managed expertise accessible in Amazon Bedrock, achieve extra management with SageMaker Coaching Jobs, scale to superior infrastructure with SageMaker HyperPod, or unlock frontier capabilities with Nova Forge for multi-turn conversations and {custom} reinforcement studying environments.
In December 2025, Amazon launched the Nova 2 household—Amazon’s first fashions with built-in reasoning capabilities. In contrast to conventional fashions that generate responses instantly, reasoning fashions like Nova 2 Lite have interaction in step-by-step downside decomposition, performing intermediate considering steps earlier than producing last solutions. This prolonged considering course of mirrors how people strategy complicated analytical duties. When mixed with RFT, this reasoning functionality turns into notably highly effective, RFT can optimize not simply what reply the mannequin produces, however the way it causes by way of issues, instructing it to find extra environment friendly reasoning paths whereas lowering token utilization. As of right now, RFT is barely supported with text-only use circumstances.
Actual-World Use Circumstances
RFT excels in eventualities the place you may outline and confirm right outcomes, however creating detailed step-by-step resolution demonstrations at scale is impractical. Under are a number of the use circumstances, the place RFT generally is a good possibility:
- Code era: You need code that’s not simply right, but in addition environment friendly, readable, and handles edge circumstances gracefully, reminiscent of qualities you may confirm programmatically by way of take a look at execution and efficiency metrics.
- Customer support: That you must consider whether or not replies are useful, keep your model’s voice, and strike the suitable tone for every scenario. These are judgment calls that may’t be diminished to easy guidelines however could be assessed by an AI choose skilled in your communication requirements.
- Different purposes: Content material moderation, the place context and nuance matter; multi-step reasoning duties like monetary evaluation or authorized doc overview; and gear utilization, the place you must train fashions when and how one can name APIs or question databases. In every case, you may outline and confirm right outcomes programmatically, even when you may’t simply reveal the step-by-step reasoning course of at scale.
- Exploration-heavy issues: Use circumstances like sport enjoying and technique, useful resource allocation, and scheduling profit from circumstances the place the mannequin makes use of completely different approaches and learns from suggestions.
- Restricted labeled knowledge eventualities: Use circumstances the place restricted labeled datasets can be found like domain-specific purposes with few expert-annotated examples, new downside domains with out established resolution patterns, expensive-to-label duties (medical analysis, authorized evaluation). In these use circumstances, RFT helps to optimize the rewards computed from the reward capabilities.
How RFT Works
RFT operates by way of a three-stage automated course of (proven in Determine 1):
Stage 1: Response era – The actor mannequin (the mannequin you’re customizing) receives prompts out of your coaching dataset and generates a number of responses per immediate—usually 4 to eight variations. This range offers the system a spread of responses to guage and study from.
Stage 2: Reward computation – As an alternative of evaluating responses to labeled examples, the system evaluates high quality utilizing reward capabilities. You’ve gotten two choices:
- Reinforcement studying by way of verifiable rewards (RLVR): Rule-based graders carried out as AWS Lambda capabilities, good for goal duties like code execution or math downside verification the place you may programmatically examine correctness.
- Reinforcement studying from AI suggestions (RLAIF): AI-based judges that consider responses primarily based on standards you configure, ultimate for subjective duties like assessing helpfulness, creativity, or adherence to model voice.
Stage 3: Actor mannequin coaching – The system makes use of the scored prompt-response pairs to coach your mannequin by way of a reinforcement studying algorithm, like Group Relative Coverage Optimization (GRPO), optimized for language fashions. The mannequin learns to maximise the chance of producing high-reward responses whereas minimizing low-reward responses. This iterative course of continues till the mannequin achieves your required efficiency.
Determine 1: Illustration of how single move of RFT works
Key Advantages of RFT
The next are the important thing advantages of RFT:
- No large, labeled datasets required – RFT solely wants prompts and a approach to consider high quality. If utilizing Bedrock RFT, you may even leverage present Bedrock API invocation logs as RFT knowledge, eliminating the necessity for specifically created datasets.
- Optimized for verifiable outcomes – In contrast to supervised fine-tuning that requires express demonstrations of how one can attain right solutions, RFT is optimized for duties the place you may outline and confirm right outcomes, however a number of legitimate reasoning paths might exist.
- Decreased token utilization – By optimizing the mannequin’s reasoning course of, RFT can scale back the variety of tokens required to perform a job, decreasing each price and latency in manufacturing.
- Safe and monitored – Your proprietary knowledge by no means leaves AWS’s safe setting in the course of the customization course of, and also you get real-time monitoring of coaching metrics to trace progress and guarantee high quality.
Implementation tiers: From easy to complicated
Amazon provides a number of implementation paths for reinforcement fine-tuning with Nova fashions, starting from totally managed experiences to customizable infrastructure. By following this tiered strategy you may match your RFT implementation to your particular wants, technical experience, and desired degree of management.

Amazon Bedrock
Amazon Bedrock supplies an entry level to RFT with a completely managed expertise that requires minimal ML experience. By the Amazon Bedrock console or API, you may add your coaching prompts, configure your reward operate as an AWS Lambda, and launch your reinforcement fine-tuning job with just some clicks. Bedrock handles all infrastructure provisioning, coaching orchestration, and mannequin deployment routinely. This strategy works effectively for simple use circumstances the place you must optimize particular standards with out managing infrastructure. The simplified workflow makes RFT accessible to groups with out devoted ML engineers whereas nonetheless delivering highly effective customization capabilities. Bedrock RFT helps each RLVR (rule-based rewards) and RLAIF (AI-based suggestions) approaches, with built-in monitoring and analysis instruments to trace your mannequin’s enchancment. To get began, see the Amazon Nova RFT GitHub repository.
Amazon SageMaker Serverless Mannequin Customization
Amazon SageMaker AI’s serverless mannequin customization is purpose-built for ML practitioners who’re prepared to maneuver past immediate engineering and RAG, and into fine-tuning LLMs for high-impact, specialised use circumstances. Whether or not the aim is enhancing complicated reasoning, domain-specific code era, or optimizing LLMs for agentic workflows together with planning, device calling, and reflection, SageMaker’s providing removes the normal infrastructure and experience obstacles that gradual experimentation. At its core, the service brings superior reinforcement studying methods like GRPO with RLVR/RLAIF to builders with out requiring complicated RL setup, alongside a complete analysis suite that goes effectively past primary accuracy metrics. Complementing this, AI-assisted artificial knowledge era, built-in experiment monitoring, and full lineage and audit path assist spherical out a production-grade customization pipeline. Deployment flexibility permits groups to ship fine-tuned fashions to SageMaker endpoints, Amazon Bedrock, or {custom} infrastructure, making it a compelling end-to-end serverless resolution for groups seeking to speed up their mannequin customization cycles and unlock the total potential of fashions like Amazon Nova in real-world purposes.
SageMaker Coaching Jobs
For groups that want extra management over the coaching course of, Amazon SageMaker Coaching Jobs provide a versatile center floor with managed compute and talent to tweak a number of hyperparameters. It’s also possible to save intermediate checkpoints and use them to create iterative coaching workflows like chaining supervised fine-tuning (SFT) and RFT jobs to progressively refine your mannequin. You’ve gotten the flexibleness to decide on between LoRA and full-rank coaching approaches, with full management over hyperparameters. For deployment, you may select between Amazon Bedrock for totally managed inference or Amazon SageMaker endpoints the place you management occasion varieties, batching, and efficiency tuning. This tier is good for ML engineers and knowledge scientists who want customization past Amazon Bedrock however don’t require devoted infrastructure. SageMaker Coaching Jobs additionally combine seamlessly with the broader Amazon SageMaker AI ecosystem for experiment monitoring, mannequin registry, and deployment pipelines. Amazon Nova RFT on SageMaker Coaching Job makes use of YAML recipe recordsdata to configure coaching jobs. You’ll be able to receive base recipes from the SageMaker HyperPod recipes repository.
Greatest practices:
- Information format: Use JSONL format with one JSON object per line.
- Reference solutions: Embody floor fact values that your reward operate will evaluate towards mannequin predictions.
- Begin small: Start with 100 examples to validate your strategy earlier than scaling.
- Customized fields: Add any metadata your reward operate wants for analysis.
- Reward Operate: Design for pace and scalability utilizing AWS Lambda.
- To get began with Amazon Nova RFT job on Amazon SageMaker Coaching Jobs, see the SFT and RFT notebooks.
SageMaker HyperPod
SageMaker HyperPod delivers enterprise-grade infrastructure for large-scale RFT workloads with persistent Kubernetes-based clusters optimized for distributed coaching. This tier builds on all of the options accessible in SageMaker Coaching Jobs—together with checkpoint administration, iterative coaching workflows, LoRA and full-rank coaching choices, and versatile deployment— on a a lot bigger scale with devoted compute assets and specialised networking configurations. The RFT implementation in HyperPod is optimized for increased throughput and sooner convergence by way of state-of-the-art asynchronous reinforcement studying algorithms, the place inference servers and coaching servers work independently at full pace. These algorithms account for this asynchrony and implement cutting-edge methods used to coach basis fashions. HyperPod additionally supplies superior knowledge filters that offer you granular management over the coaching course of and scale back the probabilities of crashes. You achieve granular management over hyperparameters to maximise throughput and efficiency. HyperPod is designed for ML platform groups and analysis organizations that must push the boundaries of RFT at scale. Amazon Nova RFT makes use of YAML recipe recordsdata to configure coaching jobs. You’ll be able to receive base recipes from the SageMaker HyperPod recipes repository.
- For extra info, see the RFT primarily based analysis to get began with Amazon Nova RFT job on Amazon SageMaker HyperPod.
Nova Forge
Nova Forge supplies superior reinforcement suggestions coaching capabilities designed for AI analysis groups and practitioners in constructing refined agentic purposes. By breaking free from single-turn interplay and Lambda timeout constraints, Nova Forge permits complicated, multi-turn workflows with custom-scaled environments working in your personal VPC. This structure offers you full management over trajectory era, reward capabilities, and direct interplay with coaching and inference servers capabilities important for frontier AI purposes that customary RFT tiers can not assist. Nova Forge makes use of Amazon SageMaker HyperPod because the coaching platform together with offering different options reminiscent of knowledge mixing with the Amazon Nova curated datasets together with intermediate checkpoints.
Key Options:
- Multi-turn dialog assist
- Reward capabilities with >15-minute execution time
- Extra algorithms and tuning choices
- Customized coaching recipe modifications
- State-of-the-art AI methods
Every tier on this development builds on the earlier one, providing a pure progress path as your RFT must evolve. Begin with Amazon Bedrock for preliminary experiments, transfer to SageMaker Coaching Jobs as you refine your strategy, and graduate to HyperPod or Nova Forge utilizing HyperPod for specialised use circumstances. This versatile structure ensures you may implement RFT on the degree of complexity that matches your present wants whereas offering a transparent path ahead as these wants develop.
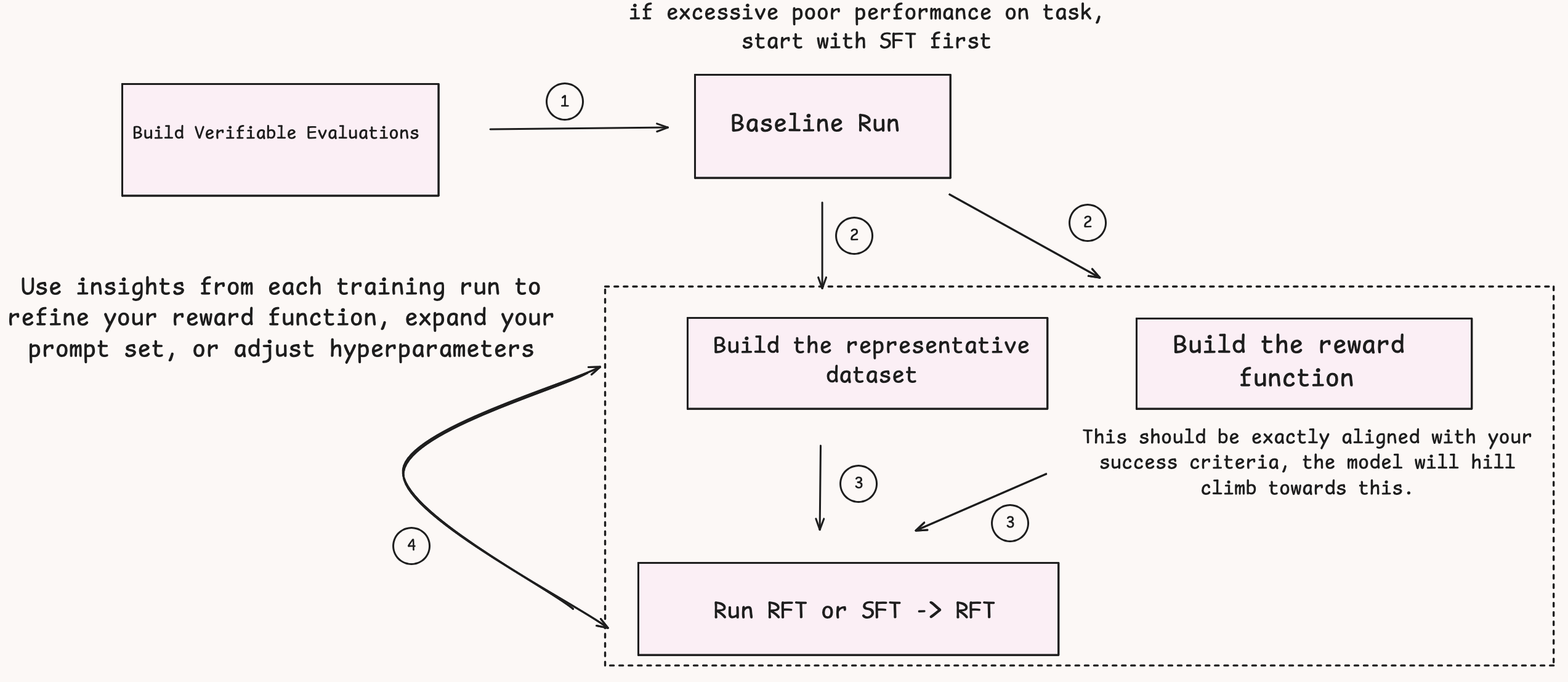
Systematic strategy to reinforcement fine-tuning (RFT)
Reinforcement fine-tuning (RFT) progressively improves pre-trained fashions by way of structured, reward-based studying iterations. The next is a scientific strategy to implementing RFT.
{kind=link}
Step 0: Consider baseline efficiency
Earlier than beginning RFT, consider whether or not your mannequin performs at a minimally acceptable degree. RFT requires that the mannequin can produce a minimum of one right resolution amongst a number of makes an attempt throughout coaching.
Key requirement: Group relative insurance policies require end result range throughout a number of rollouts (usually 4-8 generations per immediate) to study successfully. The mannequin wants a minimum of one success or a minimum of one failure among the many makes an attempt so it will probably distinguish between optimistic and unfavorable examples for reinforcement. If all rollouts constantly fail, the mannequin has no optimistic sign to study from, making RFT ineffective. In such circumstances, it’s best to first use supervised fine-tuning (SFT) to ascertain primary job capabilities earlier than making an attempt RFT. In circumstances the place the failure modes are primarily attributable to lack of understanding, in these circumstances as effectively SFT could be simpler start line, whereas if the failure modes are attributable to poor reasoning, then RFT could be a greater choice to optimize on reasoning high quality.
Step 1: Determine the suitable dataset and reward operate
Choose or create a dataset of prompts that characterize the eventualities your mannequin will encounter in manufacturing. Extra importantly, design a reward operate that:
- Crisply follows what your analysis metrics monitor: Your reward operate ought to instantly measure the identical qualities you care about in manufacturing.
- Captures what you want from the mannequin: Whether or not that’s correctness, effectivity, type adherence, or a mix of aims.
Step 2: Debug and iterate
Monitor coaching metrics and mannequin rollouts all through the coaching course of
Coaching metrics to look at:
- Reward developments over time (ought to usually enhance)
- Coverage divergence (KL) from the bottom mannequin
- Era size over time
Mannequin rollout evaluation:
- Pattern and overview generated outputs at common intervals
- Monitor how the mannequin’s conduct evolves throughout coaching steps
Frequent points and options
Points solvable instantly within the reward operate:
- Format correctness: Add reward penalties for malformed outputs
- Language mixing: Penalize undesirable language switches
- Era size: Reward applicable response lengths on your use case
Points requiring dataset/immediate enhancements:
- Restricted protection: Create a extra complete immediate set overlaying numerous problem
- Lack of exploration range: Guarantee prompts enable the mannequin to discover various eventualities and edge circumstances
RFT is an iterative course of. Use insights from every coaching run to refine your reward operate, develop your immediate set, or regulate hyperparameters earlier than the subsequent iteration.
Key RFT options and when to decide on what
This part outlines the important thing options of RFT by way of a scientific breakdown of its core parts and capabilities for efficient mannequin optimization.
Full Rank in comparison with LoRA
RFT helps two coaching approaches with completely different useful resource tradeoffs. Full Rank coaching updates all mannequin parameters throughout coaching, offering most mannequin adaptation potential however requiring extra computational assets and reminiscence. Low-Rank Adaptation (LoRA) provides parameter-efficient fine-tuning that updates solely a small subset of parameters by way of light-weight adapter layers whereas conserving many of the mannequin frozen.
LoRA requires considerably much less computational assets and leads to smaller mannequin artifacts. Importantly, LoRA fashions deployed in Amazon Bedrock assist on-demand inference—you don’t want devoted cases and solely pay for the tokens you utilize. This makes LoRA a wonderful default start line: you may rapidly iterate and validate your custom-made mannequin with out upfront infrastructure prices. As your site visitors demand grows or high-performance necessities justify the funding, you may transition to full rank coaching with devoted provisioned throughput cases for max throughput and lowest latency.
Reasoning in comparison with non-reasoning
RFT helps each reasoning and non-reasoning fashions, every optimized for various kinds of duties. Reasoning fashions generate express intermediate considering steps earlier than producing last solutions, making them ultimate for complicated analytical duties like mathematical problem-solving, multi-step logical deduction, and code era the place displaying the reasoning course of provides worth. You’ll be able to configure reasoning effort ranges—excessive for max reasoning functionality or low for minimal overhead. Non-reasoning fashions present direct responses with out displaying intermediate reasoning steps, optimizing pace and price. They’re greatest fitted to duties like chat-bot type Q&A the place you need sooner execution with out the reasoning overhead, although this will likely end in decrease high quality outputs in comparison with reasoning mode. The selection will depend on your job necessities: use reasoning mode when the intermediate considering steps enhance accuracy, and also you want most efficiency on complicated issues. Use non-reasoning mode whenever you prioritize pace and price effectivity over the potential high quality enhancements that express reasoning supplies.
When to Use RFT in comparison with SFT
| Methodology | When it really works greatest | Strengths | Limitations |
| Supervised fantastic‑tuning (SFT) | Effectively‑outlined duties with clear desired outputs, for instance, “Given X, the proper output is Y.” | • Immediately teaches factual information (for instance, “Paris is the capital of France”) • Splendid when you could have excessive‑high quality immediate‑response pairs • Supplies constant formatting and particular output buildings | • Requires express, labeled examples for each desired conduct • Could wrestle with duties that contain ambiguous or a number of legitimate options |
| Reinforcement fantastic‑tuning (RFT) | Eventualities the place a reward operate could be outlined, even when just one legitimate resolution exists | • Optimizes complicated reasoning duties • Generates its personal coaching knowledge effectively, lowering the necessity for a lot of human‑labeled examples • Permits balancing competing aims (accuracy, effectivity, type) | • Wants the mannequin to supply a minimum of one right resolution amongst a number of makes an attempt (usually 4‑8) • If the mannequin constantly fails to generate right options, RFT alone is not going to be efficient |
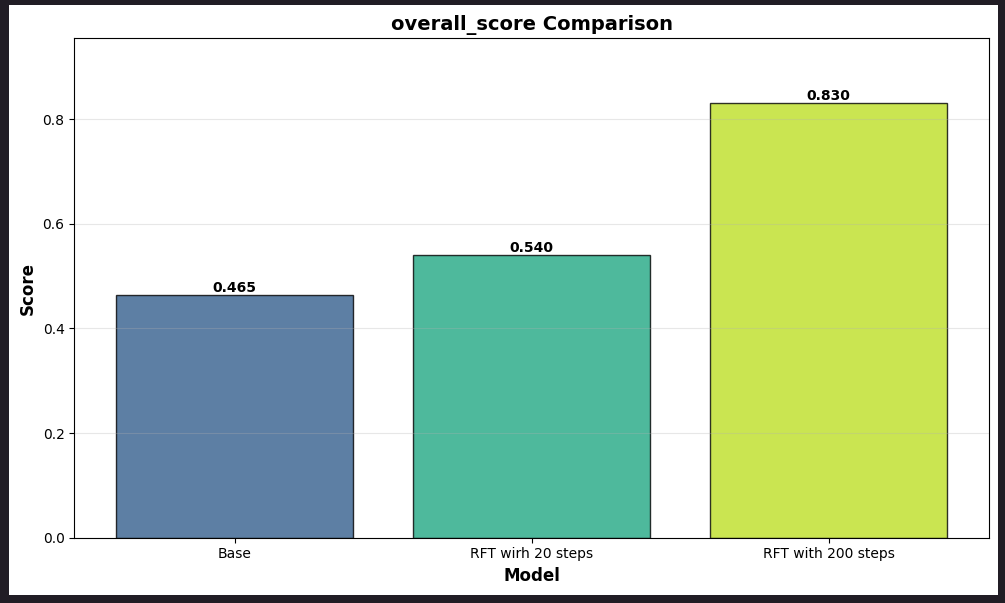
Case research: Monetary Evaluation Benchmark (FinQA) optimization with RFT
On this case research, we are going to stroll customers by way of an instance case research of FinQA, a monetary evaluation benchmark, and use that to reveal the optimization achieved in responses. On this instance we are going to use 1000 samples from the FinQA public dataset.
Step 1: Information preparation
Put together the dataset in a format that’s appropriate with RFT schema as talked about RFT on Nova. RFT knowledge follows the OpenAI conversational format. Every coaching instance is a JSON object containing. For our FinQA dataset, put up formatting an instance knowledge level in prepare.jsonl will look as proven beneath:
Required fields:
- messages: Array of conversational turns with system, person, and optionally assistant roles
- reference_answer: Anticipated output or analysis standards for reward calculation
Elective fields:
- id: Distinctive identifier for monitoring and deduplication
- instruments: Array of operate definitions accessible to the mannequin
- Customized metadata fields: Any further metadata for use whereas calculating rewards (for instance,
task_id,difficulty_level,area)
Step 2: Constructing the reward and grader operate
The reward operate is the core part that evaluates mannequin responses and supplies suggestions alerts for coaching. It have to be carried out as an AWS Lambda operate that accepts mannequin responses and returns reward scores. Presently, AWS Lambda capabilities include a limitation of as much as quarter-hour execution time. Alter the timeout of the Lambda operate primarily based in your wants.
Greatest practices:
The next are the suggestions to optimize your RFT implementation:
- Begin small: Start with 100-200 examples and few coaching epochs.
- Baseline with SFT first: If reward scores are constantly low, carry out SFT earlier than RFT.
- Design environment friendly reward capabilities: Execute in seconds, reduce exterior API calls.
- Monitor actively: Monitor common reward scores, look ahead to overfitting.
- Optimize knowledge high quality: Guarantee various, consultant examples.
Step 3: Launching the RFT job
As soon as now we have knowledge ready, we are going to launch RFT utilizing a SageMaker Coaching Jobs. The 2 key inputs for launching the RFT job are the enter dataset (input_data_s3) and the reward operate Lambda ARN. Right here we use the RFT container and RFT recipe as outlined within the following instance. The next is a snippet of how one can kick off the RFT Job: rft_training_job =rft_launcher(train_dataset_s3_path, reward_lambda_arn)
Operate:
Word: To decrease the price of this experiment, you may set occasion rely to 2 as a substitute of 4 for LoRA
Step 4: Launching the RFT Eval Job
As soon as the RFT job is accomplished, you may also take the checkpoint generated after RFT and use that to guage the mannequin. This checkpoint can then be utilized in an analysis recipe, overriding the bottom mannequin, and executed in our analysis container. The next is a snippet of how you should use the generated checkpoint for analysis. Word the identical code may also be used for working a baseline analysis previous to checkpoint analysis.
The operate could be known as utilizing the next command:
- For baselining use:
- For put up RFT analysis use:
Operate:
Step 5: Monitoring the RFT metrics and iterating accordingly
As soon as the Jobs are launched, you may monitor the Job progress in Amazon CloudWatch logs for SageMaker Coaching Jobs to take a look at the RFT particular metrics. It’s also possible to monitor the CloudWatch logs of your reward Lambda operate to confirm how the rollouts and rewards are working. It’s good apply to validate the reward Lambda operate is calculating rewards as anticipated and isn’t moving into “reward hacking” (maximizing the reward sign in unintended ways in which don’t align with the precise goal).
Assessment the next key metrics:
- Critic reward distribution metrics: These metrics (critic/rewards/imply, critic/rewards/max, critic/rewards/min) assist in discovering how the reward form appears like and if the rewards are on a path of gradual enhance.
- Mannequin exploratory conduct metrics: This metrics assist us in understanding the exploratory nature of the mannequin. The upper actor/entropy signifies increased coverage variation and mannequin’s capacity to discover newer paths.
Conclusion
With RFT you may carry out mannequin customization by way of evaluation-based studying, requiring solely prompts and high quality standards relatively than large, labeled datasets. For totally managed implementation, begin with Amazon Bedrock. In the event you want extra versatile management, transfer to SageMaker Coaching Jobs. For enterprise-scale workloads, SageMaker HyperPod supplies the required infrastructure. Alternatively, discover Nova Forge for multi-turn agentic purposes with {custom} reinforcement studying environments.
Concerning the authors