

{kind=link}
Whereas the tech people obsesses over the newest Llama checkpoints, a a lot grittier battle is being fought within the basements of information facilities. As AI fashions scale to trillions of parameters, the clusters required to coach them have turn out to be a few of the most advanced—and fragile—machines on the planet.
Meta AI Analysis staff simply launched GCM (GPU Cluster Monitoring), a specialised toolkit designed to unravel the ‘silent killer’ of AI progress: {hardware} instability at scale. GCM is a blueprint for how you can handle the hardware-to-software handshake in Excessive-Efficiency Computing (HPC).
The Downside: When ‘Customary’ Observability Isn’t Sufficient
In conventional net growth, if a microservice lags, you verify your dashboard and scale horizontally. In AI coaching, the foundations are totally different. A single GPU in a 4,096-card cluster can expertise a ‘silent failure’—the place it technically stays ‘up’ however its efficiency degrades—successfully poisoning the gradients for your complete coaching run.
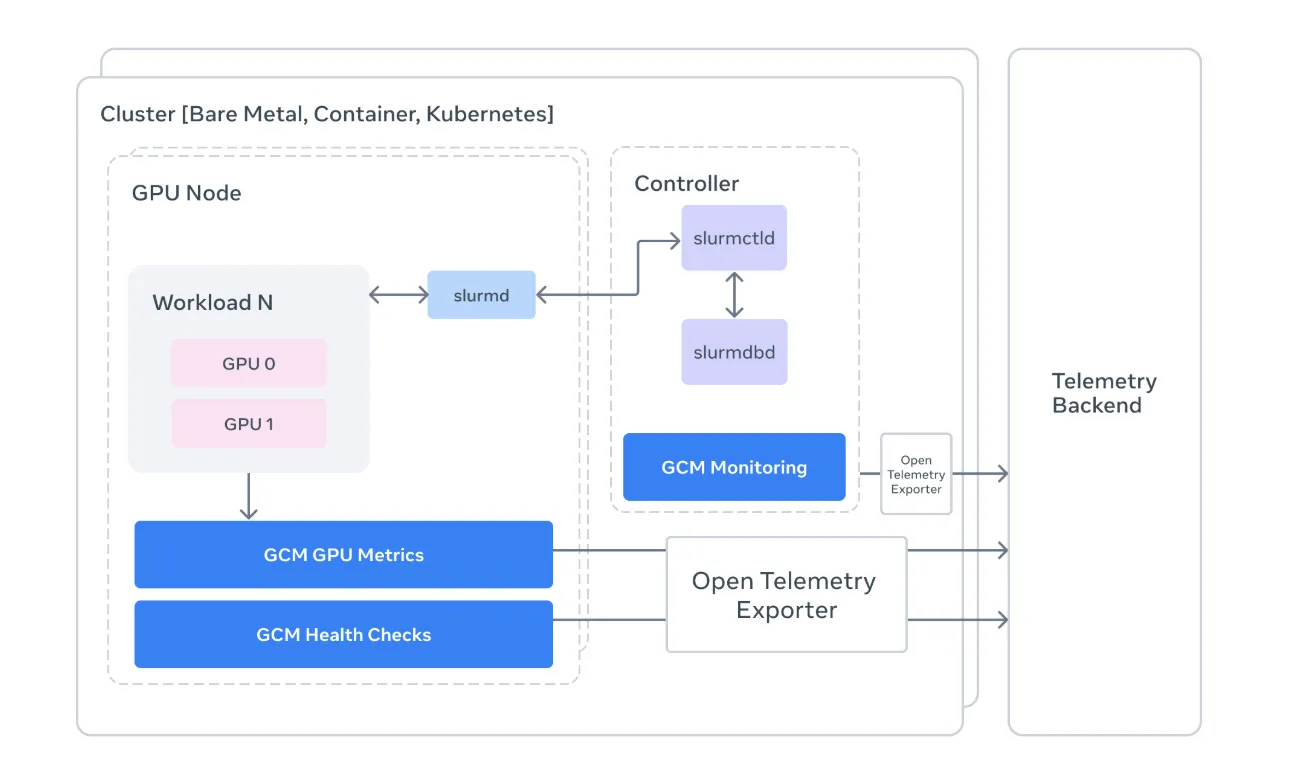
Customary monitoring instruments are sometimes too high-level to catch these nuances. Meta’s GCM acts as a specialised bridge, connecting the uncooked {hardware} telemetry of NVIDIA GPUs with the orchestration logic of the cluster.
1. Monitoring the ‘Slurm’ Manner
For devs, Slurm is the ever-present (if often irritating) workload supervisor. GCM integrates straight with Slurm to offer context-aware monitoring.
- Job-Stage Attribution: As an alternative of seeing a generic spike in energy consumption, GCM lets you attribute metrics to particular Job IDs.
- State Monitoring: It pulls information from
sacct,sinfo, andsqueueto create a real-time map of cluster well being. If a node is marked asDRAIN, GCM helps you perceive why earlier than it ruins a researcher’s weekend.
2. The ‘Prolog’ and ‘Epilog’ Technique
Probably the most technically important components of the GCM framework is its suite of Well being Checks. In an HPC surroundings, timing is every little thing. GCM makes use of two important home windows:
- Prolog: These are scripts run earlier than a job begins. GCM checks if the InfiniBand community is wholesome and if the GPUs are literally reachable. If a node fails a pre-check, the job is diverted, saving hours of ‘useless’ compute time.
- Epilog: These run after a job completes. GCM makes use of this window to run deep diagnostics utilizing NVIDIA’s DCGM (Information Heart GPU Supervisor) to make sure the {hardware} wasn’t broken through the heavy lifting.
3. Telemetry and the OTLP Bridge
For devs and AI researchers who have to justify their compute budgets, GCM’s Telemetry Processor is the star of the present. It converts uncooked cluster information into OpenTelemetry (OTLP) codecs.
By standardizing telemetry, GCM permits groups to pipe hardware-specific information (like GPU temperature, NVLink errors, and XID occasions) into trendy observability stacks. This implies you possibly can lastly correlate a dip in coaching throughput with a particular {hardware} throttled occasion, shifting from ‘the mannequin is sluggish’ to ‘GPU 3 on Node 50 is overheating.’
Underneath the Hood: The Tech Stack
Meta’s implementation is a masterclass in pragmatic engineering. The repository is primarily Python (94%), making it extremely extensible for AI devs, with performance-critical logic dealt with in Go.
- Collectors: Modular elements that collect telemetry from sources like
nvidia-smiand the Slurm API. - Sinks: The ‘output’ layer. GCM helps a number of sinks, together with
stdoutfor native debugging and OTLP for production-grade monitoring. - DCGM & NVML: GCM leverages the NVIDIA Administration Library (NVML) to speak on to the {hardware}, bypassing high-level abstractions which may cover errors.
Key Takeaways
- Bridging the ‘Silent Failure’ Hole: GCM solves a important AI infrastructure downside: figuring out ‘zombie’ GPUs that seem on-line however trigger coaching runs to crash or produce corrupted gradients on account of {hardware} instability.
- Deep Slurm Integration: In contrast to common cloud monitoring, GCM is purpose-built for Excessive-Efficiency Computing (HPC). It anchors {hardware} metrics to particular Slurm Job IDs, permitting engineers to attribute efficiency dips or energy spikes to particular fashions and customers.
- Automated Well being ‘Prolog’ and ‘Epilog’: The framework makes use of a proactive diagnostic technique, working specialised well being checks by way of NVIDIA DCGM earlier than a job begins (Prolog) and after it ends (Epilog) to make sure defective nodes are drained earlier than they waste costly compute time.
- Standardized Telemetry by way of OTLP: GCM converts low-level {hardware} information (temperature, NVLink errors, XID occasions) into the OpenTelemetry (OTLP) format. This permits groups to pipe advanced cluster information into trendy observability stacks like Prometheus or Grafana for real-time visualization.
- Modular, Language-Agnostic Design: Whereas the core logic is written in Python for accessibility, GCM makes use of Go for performance-critical sections. Its ‘Collector-and-Sink’ structure permits builders to simply plug in new information sources or export metrics to customized backend programs.
Take a look at the Repo and Venture Web page. Additionally, be at liberty to observe us on Twitter and don’t neglect to hitch our 120k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.
