

{kind=link}
Within the high-stakes world of AI infrastructure, the business has operated beneath a singular assumption: flexibility is king. We construct general-purpose GPUs as a result of AI fashions change each week, and we want programmable silicon that may adapt to the subsequent analysis breakthrough.
However Taalas, the Toronto-based startup thinks that flexibility is strictly what’s holding AI again. In line with Taalas workforce, if we would like AI to be as widespread and low cost as plastic, we now have to cease ‘simulating’ intelligence on general-purpose computer systems and begin ‘casting’ it straight into silicon.
The Drawback: The ‘Reminiscence Wall’ and the GPU Tax
The present value of operating a Giant Language Mannequin (LLM) is pushed by a bodily bottleneck: the Reminiscence Wall.
Conventional processors (GPUs) are ‘Instruction Set Structure’ (ISA) based mostly. They separate compute and reminiscence. Once you run an inference go on a mannequin like Llama-3, the chip spends the overwhelming majority of its time and power shuttling weights from Excessive Bandwidth Reminiscence (HBM) to the processing cores. This ‘knowledge motion tax’ accounts for practically 90% of the facility consumption in trendy AI knowledge facilities.
Taalas’s resolution is radical: remove the memory-fetch cycle. By utilizing a proprietary automated design movement, Taalas interprets the computational graph of a particular mannequin straight into the bodily structure of a chip. Of their HC1 (Hardcore 1) chip, the mannequin’s weights and structure are actually etched into the wiring of the silicon.

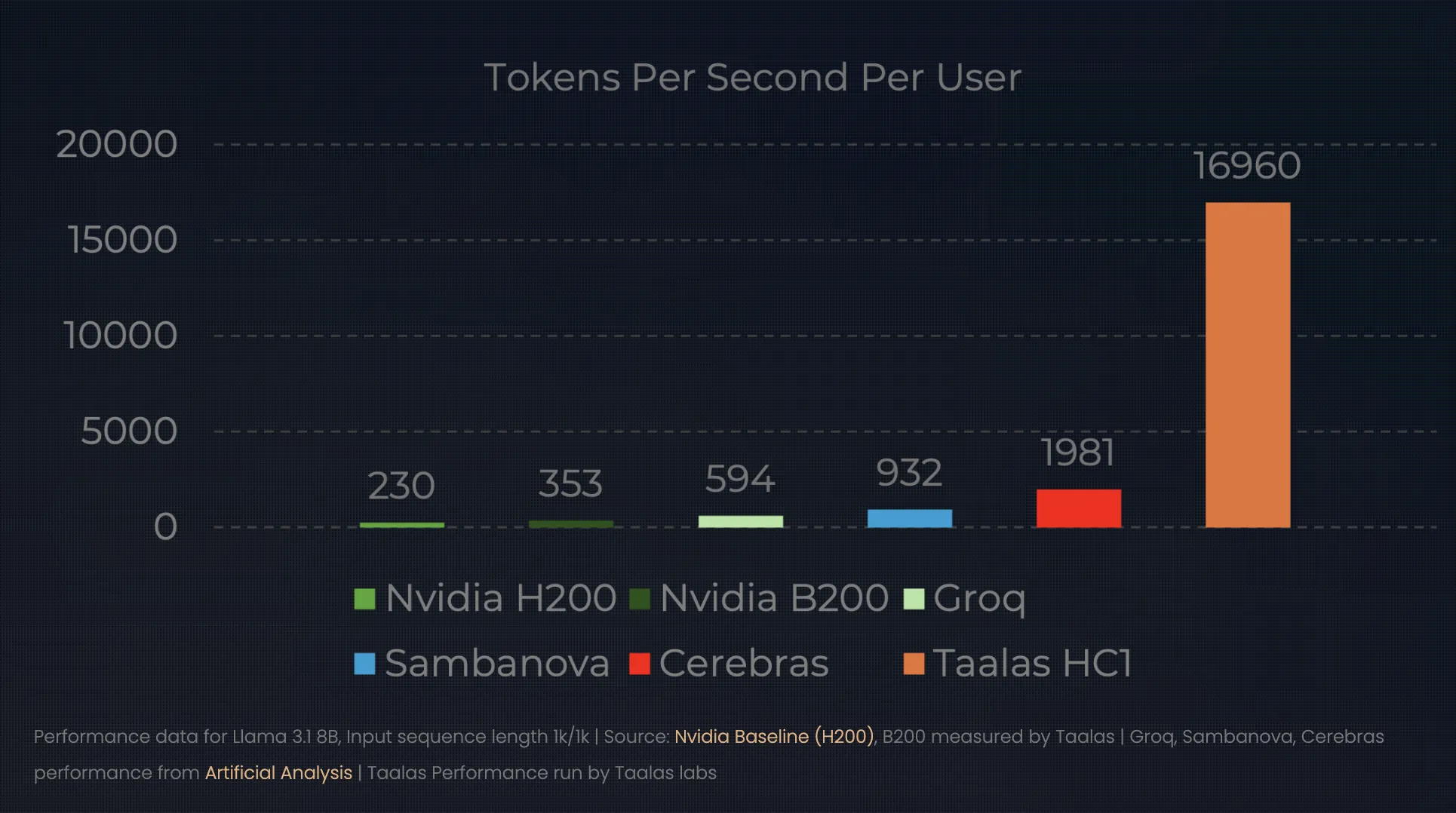
Hardcore Fashions: 17,000 Tokens Per Second
The outcomes of this ‘direct-to-silicon’ method redefine the efficiency ceiling for inference. At their newest unveiling, Taalas demonstrated the HC1 operating a Llama 3.1 8B mannequin. Whereas a top-tier NVIDIA H100 may serve a single consumer at ~150 tokens per second, the HC1 serves a staggering 16,000 to 17,000 tokens per second.
This adjustments the ‘unit economics’ of AI:
- Efficiency: A single HC1 chip can outperform a small GPU knowledge middle when it comes to uncooked throughput for a particular mannequin.
- Effectivity: Taalas claims a 1000x enchancment in effectivity (performance-per-watt and performance-per-dollar) in comparison with typical chips.
- Infrastructure: As a result of the weights are hardwired, there isn’t any want for exterior HBM or complicated liquid cooling techniques. An ordinary air-cooled rack can home ten of those 250W playing cards, delivering the facility of a complete GPU cluster in a single server field.
Breaking the 60-Day Barrier: The Automated Foundry
The apparent ‘catch’ for an AI developer is flexibility. If you happen to hardwire a mannequin right into a chip at present, what occurs when a greater mannequin comes out tomorrow? Traditionally, designing an ASIC (Software-Particular Built-in Circuit) took two years and tens of tens of millions of {dollars}.
Taalas has solved this by means of automation. They’ve constructed a compiler-like foundry system that takes mannequin weights and generates a chip design in roughly per week. By specializing in a streamlined manufacturing workflow—the place they solely change the highest metallic masks of the silicon—they’ve collapsed the turnaround time from ‘weights-to-silicon’ to simply two months.
This permits for a ‘seasonal’ {hardware} cycle. An organization might fine-tune a frontier mannequin within the spring and have 1000’s of specialised, hyper-efficient inference chips deployed by summer season.
The Market Shift: From Shovels to Stamps
This transition marks a pivotal second within the AI hype cycle. We’re transferring from the ‘Analysis & Coaching’ section—the place GPUs are important for his or her flexibility—to the ‘Deployment & Inference’ section, the place cost-per-token is the one metric that issues.
If Taalas succeeds, the AI market will break up into two distinct tiers:
- Normal-Function Coaching: Led by NVIDIA and AMD, offering the large, versatile clusters wanted to find and practice new architectures.
- Specialised Inference: Led by ‘foundries’ like Taalas, which take these confirmed architectures and ‘print’ them into low cost, ubiquitous silicon for all the things from smartphones to industrial sensors.
Key Takeaways
- The ‘Hardwired’ Paradigm Shift: Taalas is transferring from software-defined AI (operating fashions on general-purpose GPUs) to hardware-defined AI. By ‘baking’ a particular mannequin’s weights and structure straight into the silicon, they remove the necessity for conventional instruction-set overhead, successfully making the mannequin the processor itself.
- Loss of life of the Reminiscence Wall: Conventional AI {hardware} wastes ~90% of its power transferring knowledge between reminiscence and compute. Taalas’s HC1 (Hardcore 1) chip eliminates the “Reminiscence Wall” by bodily wiring the mannequin parameters into the chip’s metallic layers, eradicating the necessity for costly Excessive Bandwidth Reminiscence (HBM).
- 1000x Effectivity Leap: By stripping away the ‘programmability tax’, Taalas claims a 1,000x enchancment in performance-per-watt and performance-per-dollar. In observe, this implies an HC1 can hit 17,000 tokens per second on a Llama 3.1 8B mannequin—massively outperforming an ordinary GPU rack whereas utilizing far much less energy.
- Automated ‘Direct-to-Silicon’ Foundry: To resolve the issue of mannequin obsolescence, Taalas makes use of a proprietary automated design movement. This reduces the time to create a customized AI chip from years to simply weeks, permitting corporations to ‘print’ their fine-tuned fashions into silicon on a seasonal foundation.
- The Commodity AI Future: This expertise indicators a shift from ‘Cloud-First’ to ‘Machine-Native’ AI. As inference turns into an affordable, hardwired commodity, AI will transfer off centralized servers and into native, low-power {hardware}—starting from smartphones to industrial sensors—with zero latency and no subscription prices.
Take a look at the Technical particulars. Additionally, be happy to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as effectively.
