
")
At this time is the fifth and final entry into my replication of the Card, et al. PNAS paper. Yow will discover the others right here so as from 1 to 4:



{kind=link}
In at the moment’s put up, I conclude with evaluation of the newest batch to openAI the place I sought a steady rescoring of the unique speeches on what’s known as a “thermometer”. The values ranged from -100 (anti-immigration) to +100 (pro-immigration). I additionally had Claude Code discover 4 extra datasets that weren’t utilizing easy “-1, 0, +1” classifications like the unique Card, et al. paper needed to see if the resins why gpt-4o-mini reclassified 100,000 speeches however didn’t have any impact in any respect on the traits was due to the three-partite classification or if it was one thing else.
Within the technique of doing this, although, I observed one thing unusual and sudden. I observed that the gpt-4o-mini reclassification confirmed heaping at non-random intervals. That may be a frequent characteristic mockingly of how people reply to thermometers in surveys, nevertheless it was not one thing I had explicitly informed gpt-4o-mini to do when scoring these speeches. I focus on that under. And you’ll watch all of this by viewing the video of the usage of Claude Code to do all this right here.
Thanks once more everybody on your assist of the substack! This sequence on Claude Code, and the substack extra usually, is a labor of affection. I’m glad that a few of this has been helpful. Please take into account supporting the substack at solely $5/month!
Jerry Seinfeld’s spouse as soon as mentioned that if she needs her children to eat greens, she hides them on a pizza. That’s been the working precept of this complete sequence. I’ve been replicating a PNAS paper — Card, et al on 140 years of congressional speeches and presidential communications about immigration — not as a result of the replication is the purpose, however as a result of the replication is the pizza. The greens are Claude Code and what it may possibly do whenever you level it at an actual analysis query.
My rivalry has been easy: you can’t be taught Claude Code by way of Claude Code alone. You’ll want to see it helping within the pursuit of one thing you already wished to do. Which is why this has been two issues directly from the beginning. First, an indication of what’s potential when an AI coding agent builds and runs your pipeline. Second, an precise analysis undertaking — one the place the LLM reclassification of 285,000 speeches turned up issues I didn’t anticipate finding.
And this sequence is about that. I exploit Claude Code on the service of analysis duties as a way to see it being finished by first following a analysis undertaking. That is how I’m “sneaking veggies onto the pizza” so to talk — by making this sequence in regards to the analysis use instances, not Claude Code itself, my hope is that you just see how you should utilize Claude Code for analysis too.
Within the first two components of this sequence, we constructed a pipeline utilizing Claude Code and OpenAI’s Batch API to reclassify each speech within the Card et al. dataset. The unique paper used a fine-tuned RoBERTa mannequin. Round 7 college students at Princeton rated 7500 speeches which have been then used with RoBERTa to foretell a pair hundred thousand extra.
However we used gpt-4o-mini at zero temperature, zero-shot, no coaching information. The entire value for the unique submission was eleven {dollars}. The entire time was about two and a half hours of computation, most of it ready on the Batch API. And after I redid it a second time, it was simply one other $11 and one other couple hours. Making the entire value of all this round $22 and roughly a day’s quantity of labor.
The headline outcome was 69% settlement with the unique classifications. The place the 2 fashions disagreed, the LLM overwhelmingly pulled towards impartial — as if it had the next threshold for calling one thing definitively pro- or anti-immigration. However right here’s the factor that made it publishable slightly than simply fascinating: the combination time sequence was just about equivalent. Decade by decade, the web tone of congressional immigration speeches tracked the identical trajectory no matter which mannequin did the classifying. The disagreements cancelled out as a result of they have been roughly symmetric.
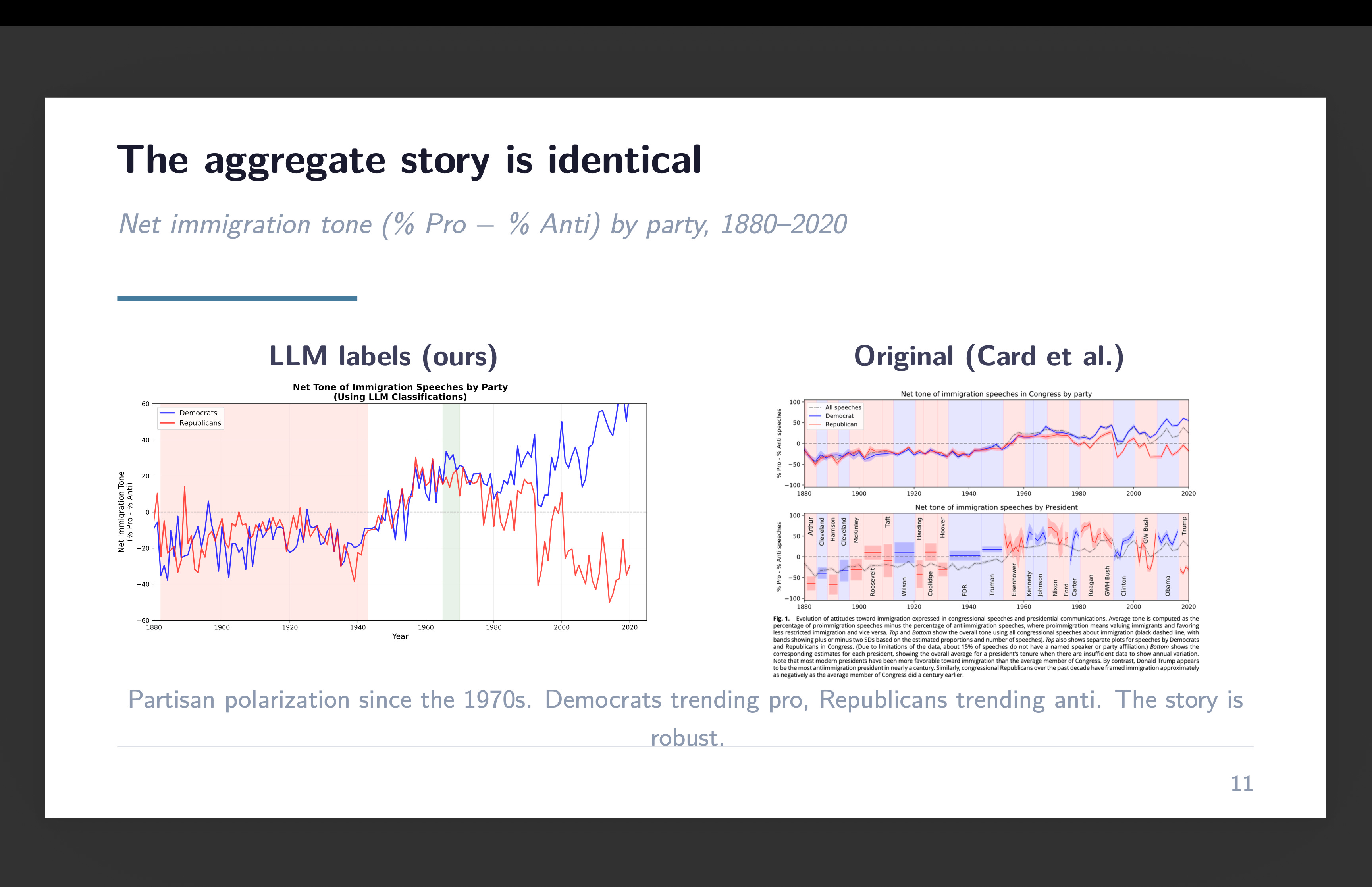
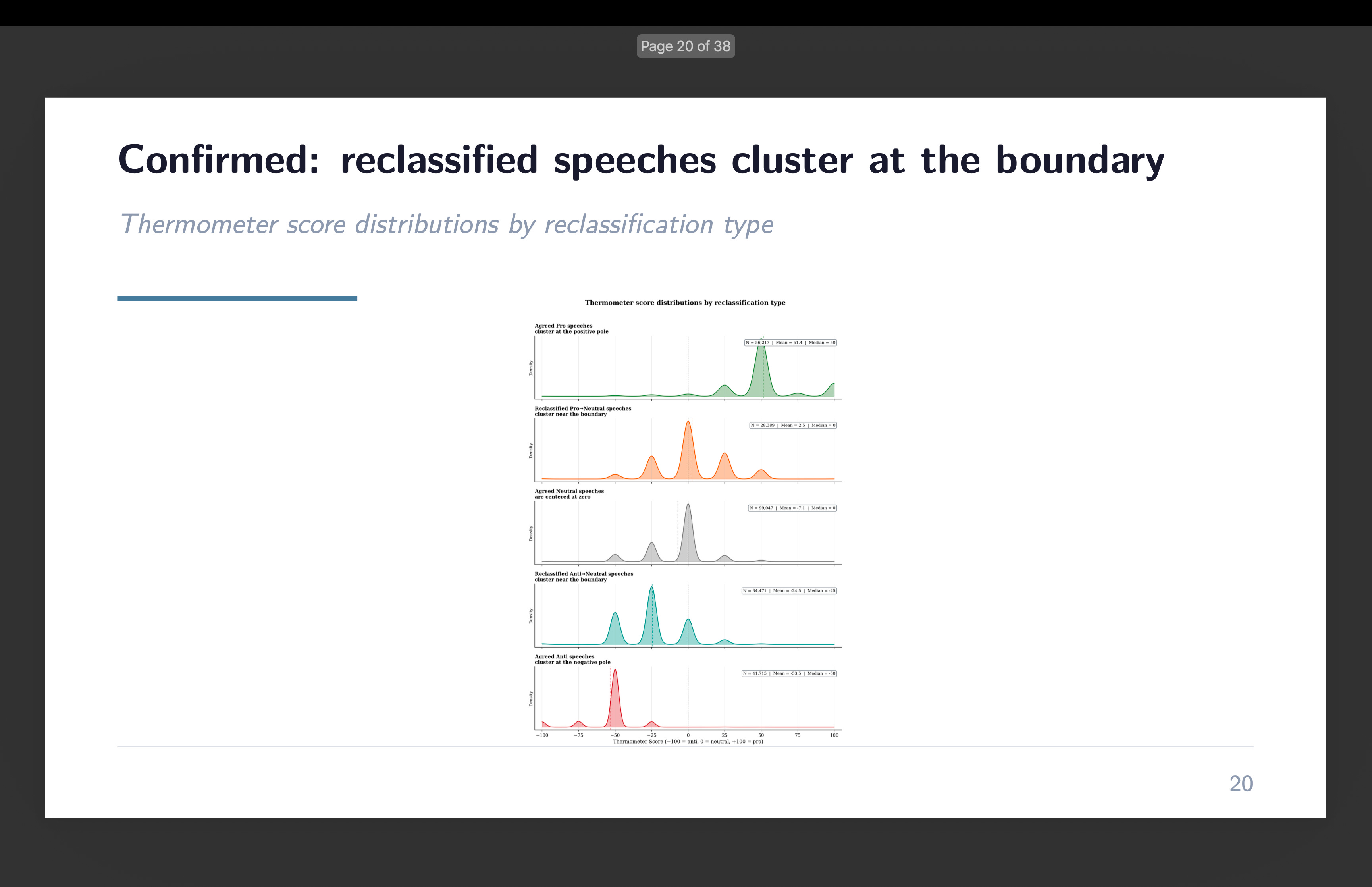
For the second submission, we wished to go deeper. As an alternative of simply asking the LLM for a label — professional, anti, or impartial — we requested it for a steady rating. A thermometer. Price every speech from -100 (strongly anti-immigration) to +100 (strongly pro-immigration). The thought was easy: if reclassified speeches actually are marginal instances, they need to cluster close to zero on the thermometer. And if the LLM is doing one thing essentially completely different from RoBERTa, the thermometer would expose it.
It labored. Speeches the place each fashions agreed on “anti” averaged round -54. Speeches each known as “professional” averaged round +48. And the reclassified speeches — those the LLM moved from the unique label to impartial — clustered nearer to zero, with technique of -25 and +2.5 respectively. The boundary instances behaved like boundary instances.
However one thing else confirmed up within the information. One thing I wasn’t searching for.
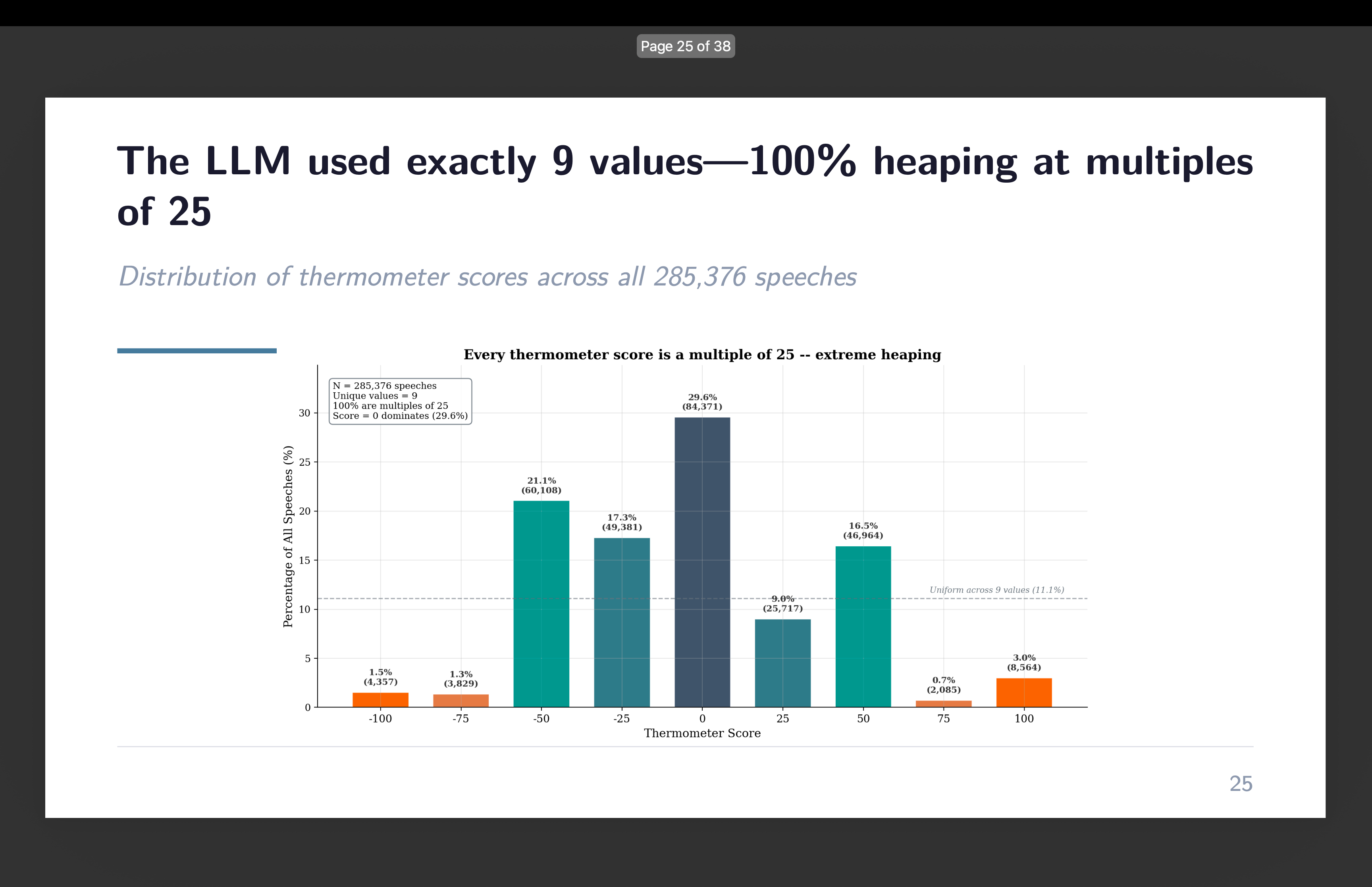
I gave gpt-4o-mini a steady scale. 200 and one potential integer values from -100 to +100. And it used 9 of them.
Each single thermometer rating — all 285,376 of them — landed on a a number of of 25. The values -100, -75, -50, -25, 0, +25, +50, +75, +100. That’s it. Not a single -30. Not one +42. Not a +17 wherever in a 3rd of 1,000,000 speeches. The mannequin spontaneously transformed a steady scale right into a 9-point ordinal.
After I noticed this, I ended the session. As a result of I acknowledged it. I had taught (my deck) about this simply yesterday mockingly in my Gov 51 class right here at Harvard.
Feeling thermometers have been utilized in survey analysis because the Sixties. The American Nationwide Election Research use them. Political scientists use them to measure attitudes towards candidates, events, teams. You give somebody a scale from 0 to 100 and ask them to price how warmly they really feel about one thing. The instrument is in every single place.
And the instrument has a well-documented drawback: people heap. They spherical to focal factors. Within the 2012 ANES, at the least 95% of feeling thermometer responses have been rounded to multiples of 5. The modal responses are all the time 0, 50, and 100. Folks don’t use the total vary. They satisfice — a time period from Herbert Simon by the use of Jon Krosnick’s satisficing idea of survey response. Whenever you’re unsure about the place you fall on a 101-point scale, you attain for the closest spherical quantity that feels shut sufficient.
That is so well-known that it turned a part of a fraud detection case. The day earlier than I observed the heaping in our information, I’d been instructing Broockman, Kalla, and Aronow’s “irregularities” paper — the one which documented issues with the LaCour and Inexperienced research in Science. A part of their proof that LaCour’s information was fabricated concerned thermometer scores. The unique CCAP survey information confirmed the anticipated heaping sample — massive spikes at 0, 50, 100. LaCour’s management group information didn’t. It appeared he’d injected small random noise from a standard distribution, which smoothed the heaps away. The heaping was so anticipated that its absence was a purple flag.

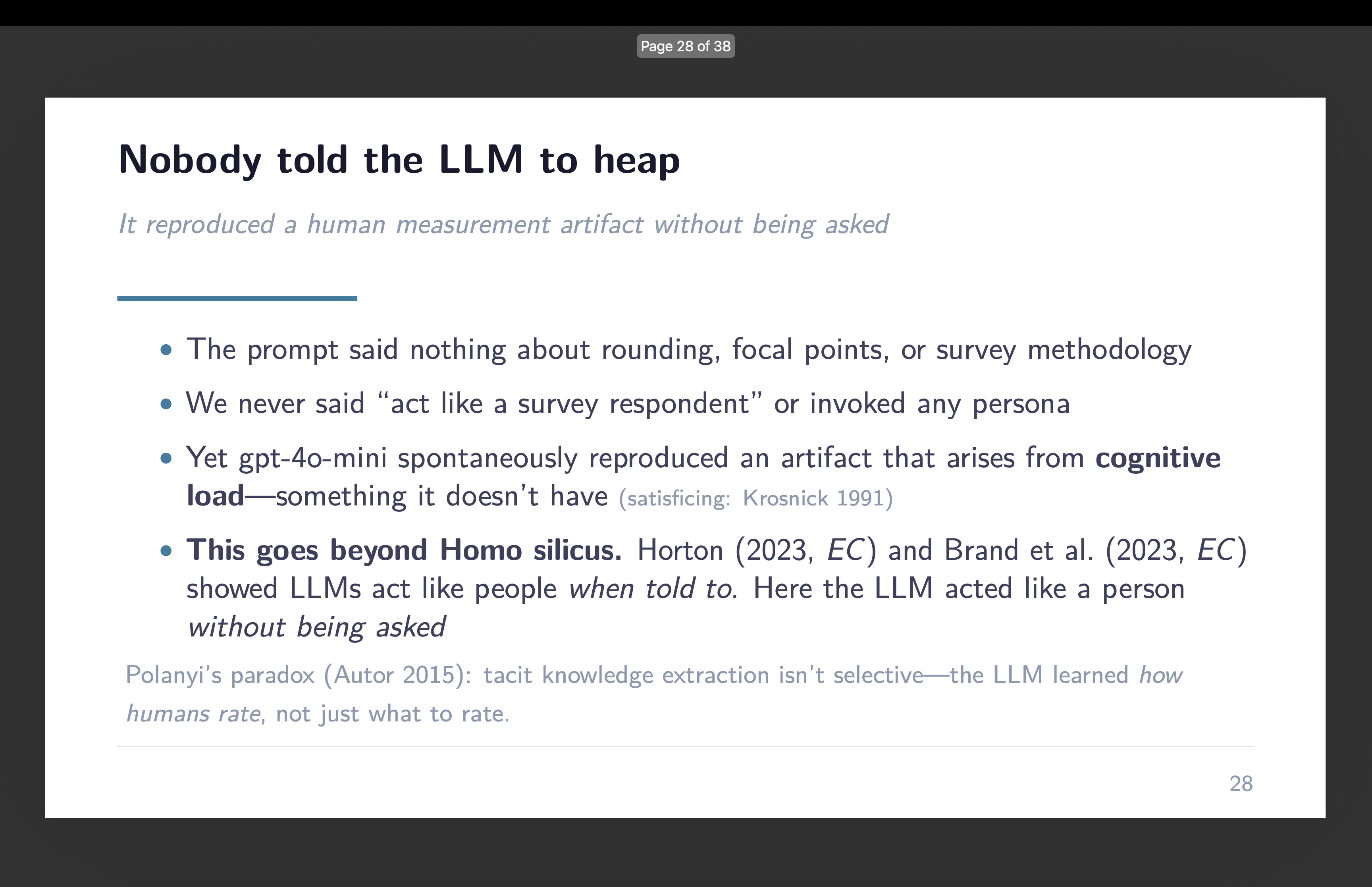
Right here’s what stops me. The unique Card et al. paper didn’t use a thermometer. RoBERTa doesn’t produce scores on a sense thermometer scale. I invented the -100 to +100 framing for this undertaking. The immediate mentioned nothing about survey methodology, nothing about rounding, nothing about appearing like a survey respondent. I gave gpt-4o-mini a classification activity with a steady output area and it voluntarily compressed that area in precisely the way in which a human survey respondent would.
The LLM doesn’t have cognitive load. It doesn’t get drained. It doesn’t expertise the uncertainty that makes people attain for spherical numbers. Satisficing is a idea about bounded rationality — in regards to the hole between what you’d do with infinite processing capability and what you truly do with a organic mind that has different issues to fret about. The LLM has no such hole. And but it heaped.
This goes past what others have documented. John Horton’s “Homo Silicus” work confirmed that LLMs reproduce outcomes from basic financial experiments — they exhibit equity norms, established order bias, the type of habits we anticipate from human topics — at roughly a greenback per experiment. Model, Israeli, and Ngwe confirmed that GPT reveals downward-sloping demand curves, constant willingness-to-pay, state dependence — the constructing blocks of rational client habits. Each of these findings are hanging. However in each instances, the researchers informed the LLM to behave like an individual. They gave it a persona. They mentioned “you’re a participant on this experiment” or “you’re a client evaluating this product.”
I didn’t inform gpt-4o-mini to behave like something. I informed it to categorise speeches. And it categorized them — accurately, usefully, in a manner that replicates the unique paper’s combination findings. However it additionally, with out being requested, reproduced a measurement artifact that arises from human cognitive limitations it doesn’t possess.
David Autor has been writing about what he calls Polanyi’s paradox — the thought, from Michael Polanyi, that we all know greater than we will inform. People do issues they will’t articulate guidelines for. We acknowledge faces, parse sarcasm, decide whether or not a political speech is hostile or pleasant, and we do it by way of tacit information — patterns absorbed from expertise that by no means get written down as specific directions.
Autor’s perception about LLMs is that they seem to have cracked this paradox. They extract tacit information from coaching information. They will do issues nobody ever wrote guidelines for as a result of they discovered from the gathered output of people doing these issues.
However right here’s what the heaping suggests: the extraction isn’t selective. When the LLM discovered consider political speech on a numeric scale, it didn’t simply be taught what to price every speech. It discovered how people price. It absorbed the content material information and the measurement noise collectively, as a bundle. The heaping, the rounding, the focal-point heuristics — these got here alongside for the journey. No one educated gpt-4o-mini on survey methodology. No one labeled a dataset with “that is what satisficing seems like.” The mannequin discovered it the way in which people be taught it: implicitly, from publicity, with out anybody pointing it out.
I believe that is the type of tacit information Autor has in thoughts. The issues nobody ever informed anybody to do, as a result of nobody knew they have been doing them.
There was additionally a sensible query hanging over the entire undertaking: does any of this depend upon the truth that we had three classes? Professional, anti, and impartial type a pure spectrum with a middle that may take in errors. Possibly the symmetric cancellation solely works as a result of impartial sits between the opposite two.
So we examined 4 benchmark datasets: AG Information (4 classes, no ordering), SST-5 (5-level sentiment with a middle), DBpedia-14 (14 ontological classes), and 20 Newsgroups (20 unordered subjects). Similar methodology — zero-shot gpt-4o-mini, temperature zero, Batch API. Complete value for all 4: a greenback twenty-six.

Settlement ranged from 55% on 20 Newsgroups to 97% on DBpedia-14. The mechanism wasn’t tripartite construction. It was class separability — how distinct the classes are from one another. When the classes are semantically crisp (firm vs. faculty vs. artist in DBpedia), the LLM nails it. After they’re fuzzy and overlapping (distinguishing speak.politics.weapons from speak.politics.misc in Newsgroups), it struggles. The immigration outcome generalizes, however not as a result of three classes are particular. It generalizes as a result of the classes occur to be fairly separable.
Another factor. Whereas we have been doing this work, Asirvatham, Mokski, and Shleifer launched an NBER working paper known as “GPT as a Measurement Instrument.” They current a software program bundle — GABRIEL — that makes use of GPT to quantify attributes in qualitative information. One among their check instances is congressional remarks. The paper supplies impartial proof that GPT-based classification can match or exceed human-annotated approaches for the type of political textual content evaluation we’ve been doing.
I point out this to not declare precedence however to notice convergence. A number of teams are arriving on the identical place from completely different instructions. The LLM isn’t only a classifier. It’s a measurement instrument. And like all measurement devices, it has properties — together with properties no one designed into it.
I began this sequence wanting to indicate folks what Claude Code can do. I nonetheless suppose one of the best ways to be taught it’s to look at it work on one thing actual. However the one thing actual saved producing surprises. The 69% settlement that doesn’t matter as a result of the disagreements cancel. The thermometer scores that cluster on the boundary. And now this — a measurement artifact that no one requested for, that no one programmed, that emerges from the identical tacit information that makes the classification work within the first place.
A 9-point scale hidden inside a 201-point scale. The LLM measures like a human, right down to the errors. And I don’t suppose it is aware of it’s doing it any greater than we do.

Effectively, that’s the top of this replication/extension of the PNAS paper. I wished folks to see with their very own eyes the usage of Claude Code to do classification of texts utilizing gpt-4o-mini at OpenAI. It’s not an easy factor. Listed here are two slides about it:
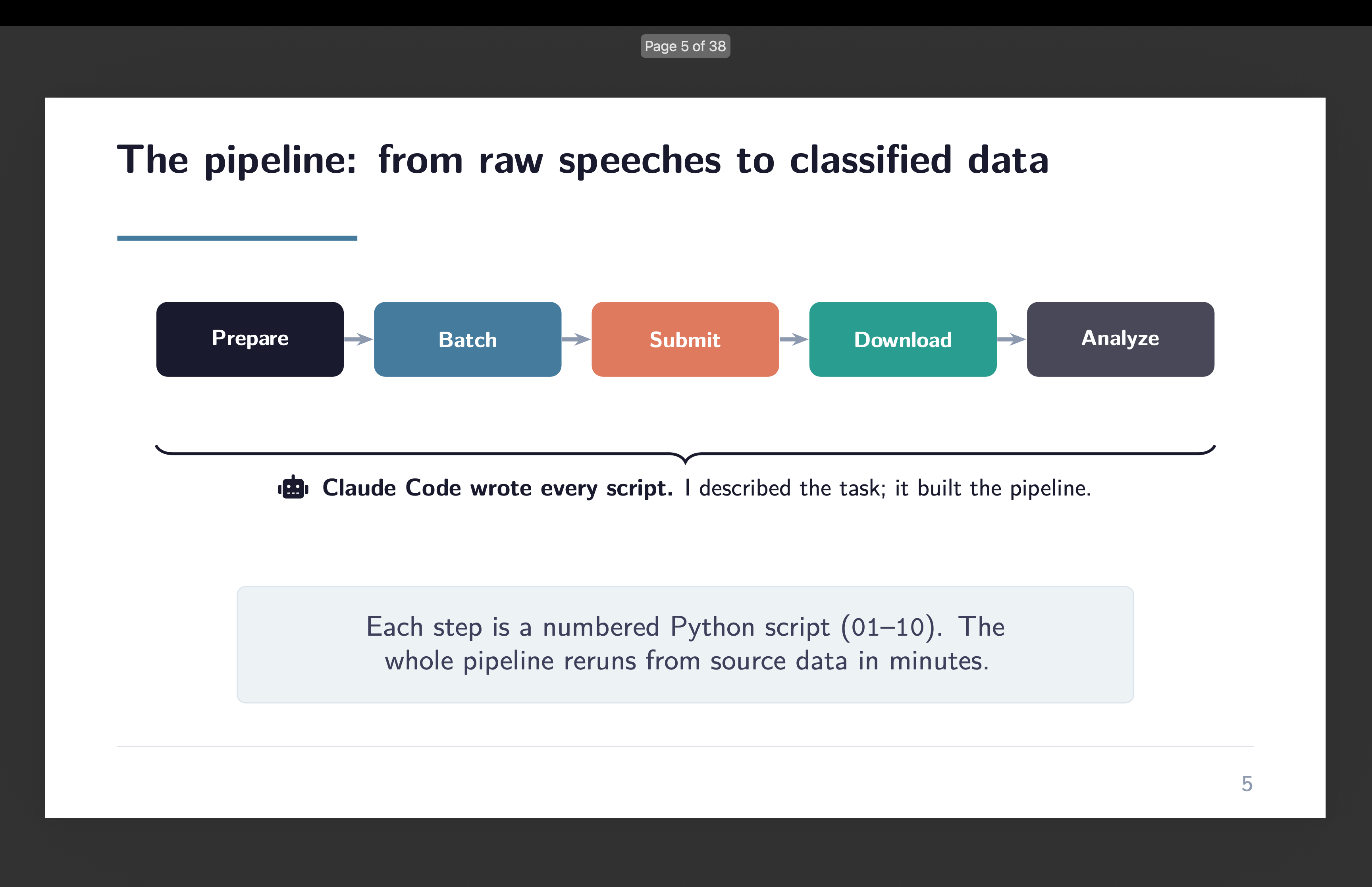

And in order that’s finished. I hope that the video stroll throughs, and the reasons, in addition to the decks (like this remaining one) have been useful for a few of you on the fence about utilizing Claude Code. Not solely do I believe that it’s a useful productiveness enhancing instrument — to be trustworthy, I believe it’s unavoidable. It’s most likely on par with the transfer from utilizing punch playing cards for empirical work to what we have now now. Possibly even moreso. However having supplies that enable you to get there I believe is for many individuals actually important as a lot of the materials till not too long ago was by engineers for engineers, and admittedly, I believe Claude Code could also be placing these particular duties into pure automation which means even these explainers may fade.
However now I’ve to determine what I’m going to do with these findings! So we’ll see if I can work out a paper out of all this bumbling round that you just noticed. Undecided. I both am staring proper at a small contribution or I’m seeing a mirage and nothing is there, however I’m going to suppose on that subsequent. I’m open to ideas! Have an incredible weekend! Keep hydrated because the flu could also be going round.