
")
{kind=link}
I used gpt-4o-mini to duplicate the textual content classification from Card et al.’s PNAS paper on 140 years of immigration rhetoric. Right here’s what occurred:
-
Complete Value of this Train: $10.99
-
Complete Time: 1 hour arrange (yesterday’s video), 2.6 hours (we anticipated 24), 1 hour of research in the present day = 4.6 hours.
-
Settlement with authentic classifier: 69%
-
Key discovering: The polarization story is strong—each classifiers present Democrats and Republicans diverging sharply because the Nineteen Seventies
Backside line: LLMs can considerably replicate skilled classifier outcomes at a fraction of the fee. The substantive conclusions survive. For those who’re doing exploratory textual content evaluation with out sources to fine-tune a customized mannequin, that is now a viable path.
The catch: The LLM is extra “cautious”—when unsure, it calls issues NEUTRAL as a substitute of choosing a facet. Direct PRO↔ANTI disagreements are uncommon (solely 4%).
The video is under, and a phrase of thanks to all paying subscribers and people who have gifted the substack and shared the posts. Thanks! This substack is a labor of affection, and I actually take pleasure in sharing what I’m studying about utilizing Claude Code for quantitative social scientific analysis. So thanks everybody on your help.
Now for the small print.
In Half 1 (hyperlink under), I described an experiment: may Claude Code assist me replicate the textual content classification from Card et al.’s PNAS paper on 140 years of immigration rhetoric? And in yesterday’s publish, Claude Code internet crawled to seek out the replication package deal, organized my directories, got here up with a plan, cracked open the information, submitted json information in batch to OpenAI to have the gpt-4o-mini do a one-shot evaluation of 304,995 speeches able to classify. I used a batch job which is 50% cheaper than doing it one request at a time, plus it’s 305k speeches so you possibly can’t realistically try this anyway. However there was a number of uncertainty as to what would occur.
Initially, yesterday, Claude Code informed me that it could take 24 hours for the evaluation to be accomplished, however it truly took solely 2.6 hours and doubtless much less as a result of I needed to resubmit a few batches that had failed and solely found that was the case at round 2.5 hours. So I wasn’t positive how lengthy it had been finished is my level once I resent in these final two batches. Anyway, it’s finished, the outcomes are in, and I filmed myself analyzing it, in addition to making a deck (which I am going via within the video).
Right here’s what we discovered.
First, simply so this has its personal part and like I stated, once I submitted the batch job, I anticipated to attend. And that’s as a result of OpenAI’s documentation says batch jobs can take “as much as 24 hours.” I believed initially that when Claude Code informed me, due to this fact, it could possible take 24 hours, it was as a result of he did some again of the envelope calculation, however no. he was simply counting on the time stamp. I figured I’d verify again the following morning. However once I checked the time stamps, it had taken round 2 1/2 hours to do it.
That’s not a typo. Two and a half hours to categorise almost 300,000 speeches.
For context: the unique paper’s authors needed to fine-tune a RoBERTa mannequin on 7,626 human annotations, then run inference on their complete corpus. That’s weeks of labor in case you embody the annotation time, possibly extra relying on what number of RAs they most likely needed to rent to try this annotation.
However that’s not what we did. I truly initially thought in actual fact that we had been utilizing the 7,626 human annotations on this train, however we weren’t. Moderately we did a zero-shot replication . For eleven {dollars}.
Let me provide the headline quantity first, then we’ll unpack what it means.
gpt-4o-mini agreed with the unique RoBERTa classifier on 69% of speeches.
Is that good? It is determined by your baseline.
Right here’s what helped me calibrate: the unique paper experiences that human annotators agreed with one another at Krippendorff’s α = 0.48. That’s thought-about “average” settlement in content material evaluation. People themselves usually disagreed about whether or not a speech was pro-immigration, anti-immigration, or impartial.
If even people can’t reliably agree, how a lot ought to we count on two totally different ML programs to agree?
69% isn’t good. But it surely’s much better than probability (which might be ~33% for a three-class downside). And it’s within the ballpark of what you’d count on given the underlying ambiguity of the duty.
Right here’s the complete image:
Let me stroll you thru the best way to learn this.
Every row is an authentic RoBERTa label. Every column is what gpt-4o-mini categorized it as. The odds are row percentages—of all speeches RoBERTa labeled as X, what fraction did the LLM label as Y? They need to sum to 100% studying let to proper as a result of they’re treating the unique classification because the “pattern area” so to talk after which breaking apart the share of complete new classification into the three totally different classes all of that are mutually unique.
The diagonal is settlement between outdated and new classifications. NEUTRAL has the best settlement (85%). PRO has first rate settlement (63%). ANTI has the bottom (51%).
The off-diagonal tells you about systematic disagreements. And right here’s the attention-grabbing sample:
When gpt-4o-mini disagrees with RoBERTa, it nearly at all times strikes towards NEUTRAL.
-
Of speeches RoBERTa known as PRO: 63% the LLM additionally known as PRO, however 33% the LLM known as NEUTRAL
-
Of speeches RoBERTa known as ANTI: 51% the LLM additionally known as ANTI, however 44% the LLM known as NEUTRAL
The LLM is extra cautious. When it’s unsure, it hedges towards the center class.
Right here’s what anxious me entering into: what if the 2 classifiers basically disagreed about tone? What if speeches RoBERTa known as PRO-IMMIGRATION, the LLM known as ANTI?
That might be a major problem. It will imply the classifiers have incompatible understandings of political language.
The info is reassuring:
-
PRO → ANTI: 3.7%
-
ANTI → PRO: 4.9%
Direct polarity flips are uncommon. When the classifiers disagree, they normally disagree about whether or not one thing is impartial vs. opinionated—not about which path the opinion factors.
This issues for the substantive findings. For those who’re utilizing these classifications to trace partisan polarization over time, what you actually care about is whether or not a speech is clearly professional, clearly anti, or ambiguous. The 2 classifiers largely agree on that construction.
Let me present you Determine 1 from the unique paper:
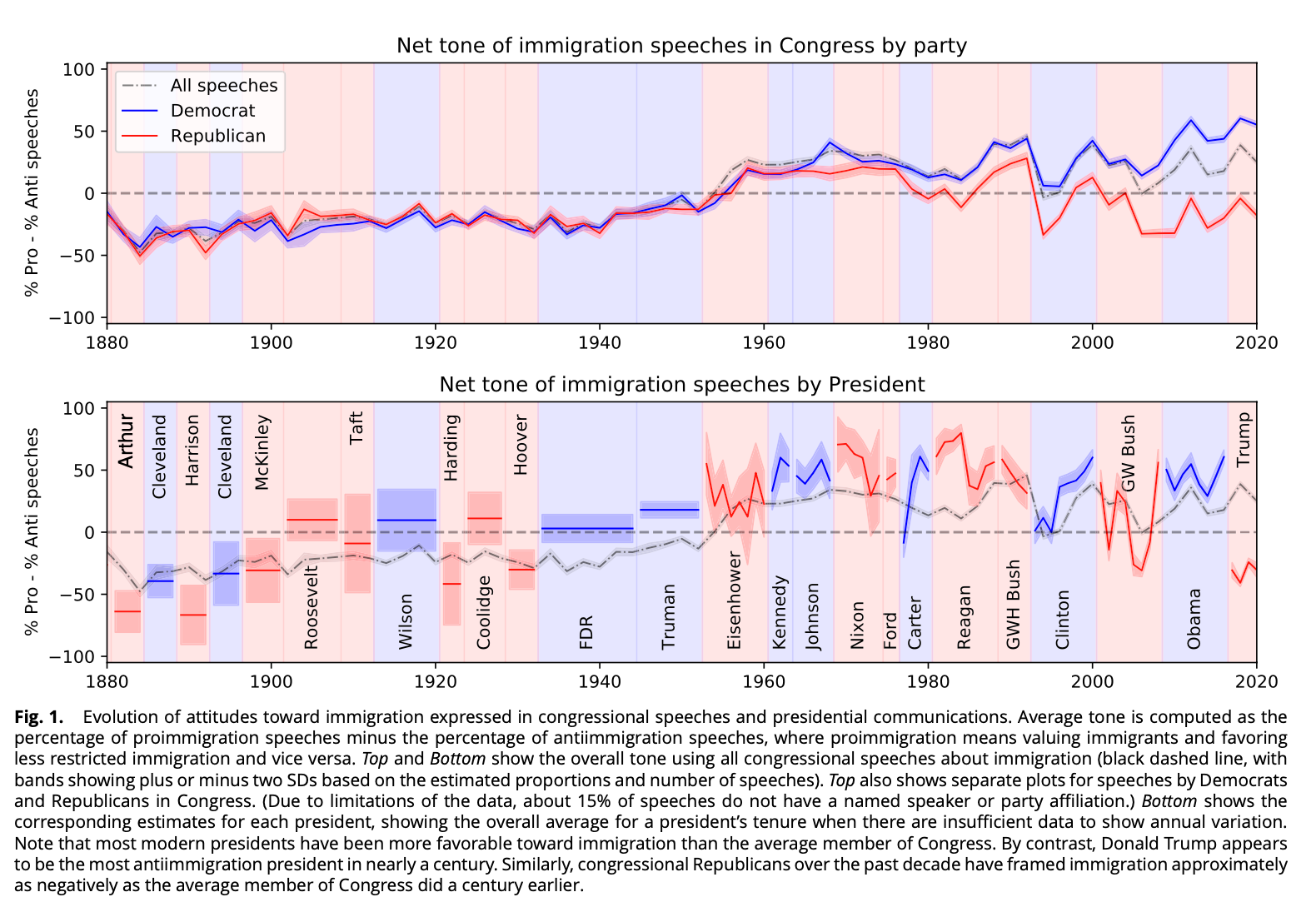
That is the important thing discovering: Democrats and Republicans have polarized sharply because the Nineteen Seventies. Democrats use more and more optimistic language about immigrants. Republicans use language as damaging because the Nineteen Twenties quota period.
Now right here’s the identical determine utilizing our LLM classifications:
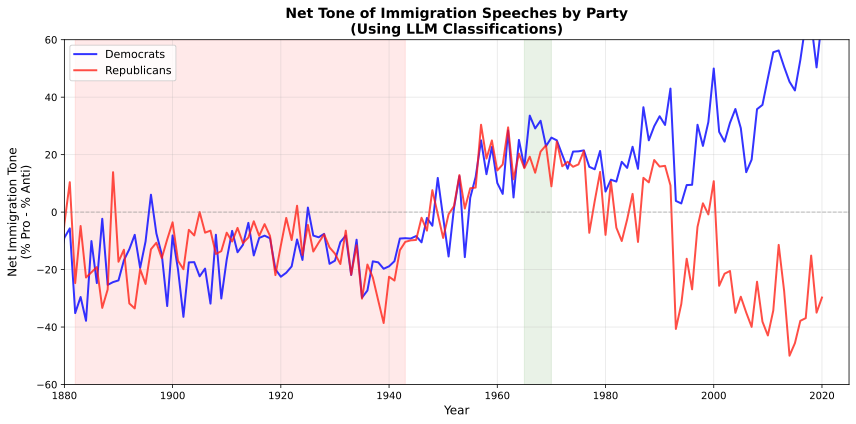
The polarization story is strong.
Each classifiers present the identical fundamental sample:
-
Partisan divergence beginning within the Nineteen Seventies
-
Democrats trending extra optimistic
-
Republicans trending extra damaging
-
The hole widening over time
The magnitudes differ—the LLM model reveals extra volatility, particularly within the early interval. However the form of the story is identical.
That is an important discovering for anybody questioning whether or not LLM-based classification can replicate conventional NLP outcomes. The qualitative conclusions maintain up. A researcher utilizing gpt-4o-mini would attain the identical substantive interpretation as the unique authors.
I used to be curious whether or not the patterns seemed totally different for my residence state, Texas, so I ran the identical evaluation restricted to Texas congressional speeches:
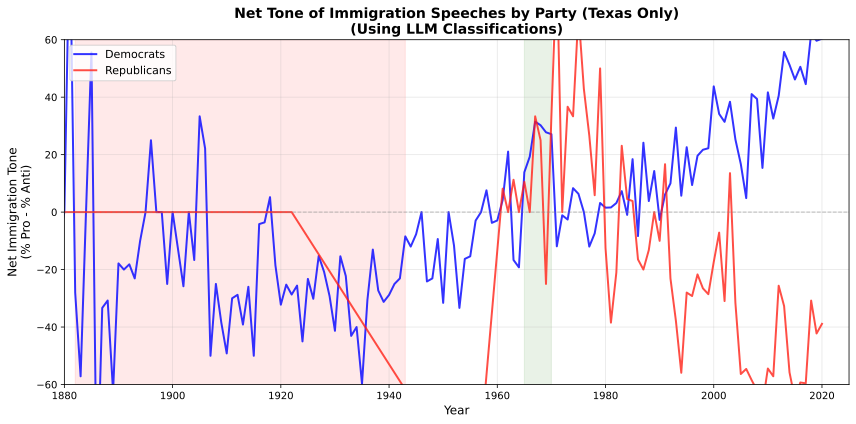
It’s noisier, and I believe there should not be many Republican Texas congressional speeches within the information earlier than the second half of the twentieth century. And when there’s any speeches by Texans, they’re Democrats and curiously, they’re damaging in the direction of immigration. However that modifications after the warfare and Democrats in Texas grow to be more and more extra optimistic. There’s an enormous pro-immigration Texas spike within the mid-Nineteen Seventies, however the identical polarization hole occurs with Texas as occurs nationally beginning round 1980.
So, the polarization story holds, although with extra noise (smaller pattern). And Texans being extra damaging in the direction of immigration seems to be a little bit of a posh historic story that I’d like to dig into extra however most likely received’t.
The unique paper additionally analyzed how tone various by the nation of origin being mentioned—Mexico, China, Italy, and many others. We replicated that:
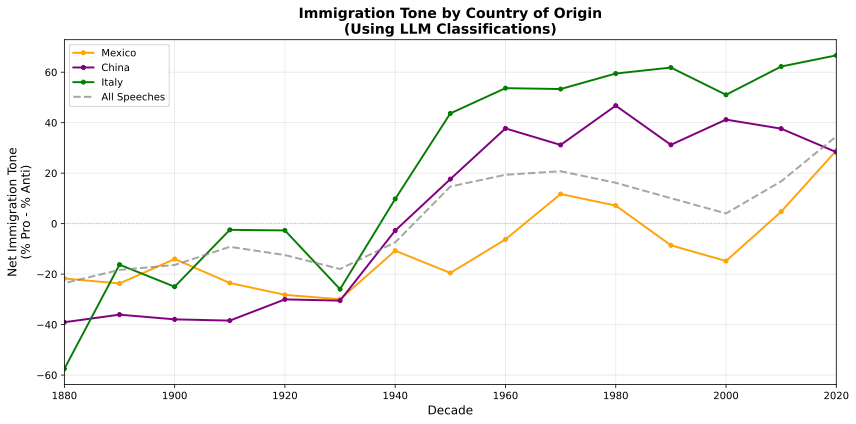
Now evaluate to the unique:
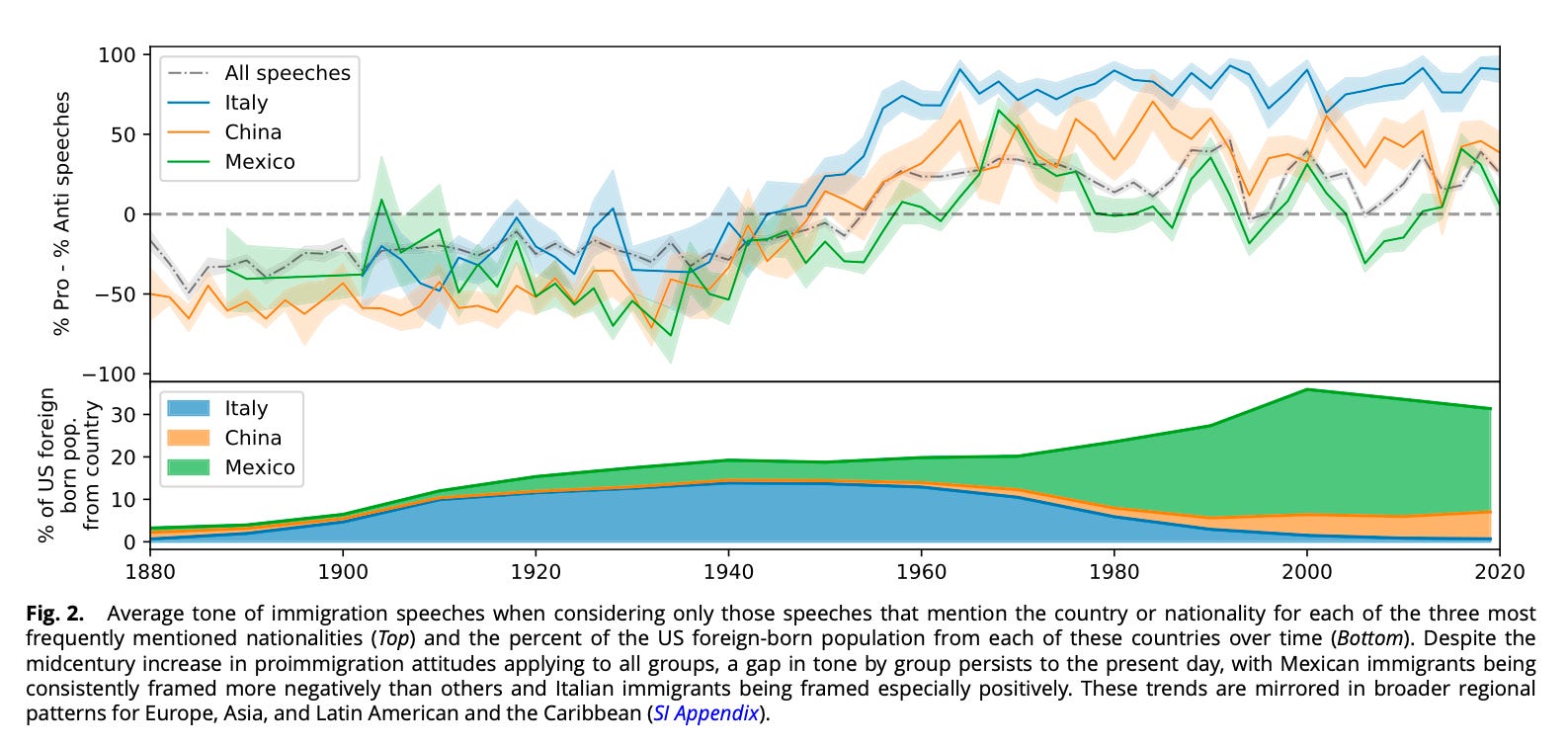
Discover the way it isn’t merely that the general developments match between the unique Roberta classification. Moderately, it’s even the ordering that’s the identical. Discover how within the authentic, it was Italy>China>Mexico, which is identical ordering because the LLM classification. Different findings:
-
China: Most damaging within the early interval (Chinese language Exclusion Period), bettering after the Nineteen Sixties
-
Mexico: Comparatively secure traditionally, with a dip within the trendy period (border politics)
-
Italy: Most optimistic general, particularly after WWII (”mannequin minority” framing)
And the LLM captured the country-specific patterns with none fine-tuning. It understood that speeches mentioning “Chinese language” in 1890 had totally different connotations than speeches mentioning “Chinese language” in 1990.
Let me be clear about one thing: this was not an apples-to-apples comparability.
RoBERTa (the unique):
-
Fantastic-tuned on 7,626 human-labeled examples
-
Skilled particularly for this job
-
Optimized to match annotator judgments
-
~65% accuracy on held-out information
gpt-4o-mini (our replication):
-
Zero-shot (no task-specific coaching)
-
Common language mannequin
-
Inferring the duty from a immediate
-
No publicity to the unique annotations
The RoBERTa mannequin was taught what pro-immigration and anti-immigration imply within the context of this particular corpus. gpt-4o-mini needed to determine it out from first ideas.
Provided that asymmetry, 69% settlement is definitely spectacular. The LLM introduced real language understanding to the duty, not simply sample matching on the particular options the RoBERTa mannequin discovered.
Greatest I can inform, what’s going on right here is that after they disagree, it’s at these “marginal speeches” that had been proper on the sting between anti and impartial, or professional and impartial. And if you reclassify them, you’re largely pushing the marginal speeches into the impartial territory. Which I believe most likely means they’re roughly random within the information, and as such the sign coming via from the professional and anti within the authentic classification is fairly robust leaving the general patterns intact.
-
LLMs can considerably replicate skilled classifier outcomes.
69% settlement isn’t good, however it’s adequate that the substantive findings survive. For those who’re doing exploratory textual content evaluation and don’t have sources to fine-tune a customized mannequin, gpt-4o-mini is a viable possibility.
-
The polarization discovering from Card et al. is strong.
Each classifiers inform the identical story about partisan divergence. This will increase my confidence within the authentic paper’s conclusions. The discovering isn’t an artifact of their particular mannequin.
-
LLMs are extra conservative.
gpt-4o-mini most popular NEUTRAL when unsure. That is most likely good conduct—it’s higher to say “I don’t know” than to confidently guess improper. But it surely means LLM-based classification might underestimate the proportion of clearly opinionated textual content.
-
Direct polarity flips are uncommon.
The classifiers hardly ever known as the identical speech each PRO and ANTI. After they disagreed, it was normally about whether or not one thing was impartial vs. opinionated. That is reassuring for anybody utilizing these instruments for sentiment evaluation.
-
LLM was cheaper
And maybe an important factor — the fee. One thing like 4 hours, begin to end, and solely $11. The onerous half was due to this fact most likely in getting the information — however I wager you that too is a quest we may undertake at appreciable velocity given it’s totally potential these can be found to us such that Claude Code would’ve crawled and scraped the speeches, or they’re saved in some warehouse someplace. Although possibly this crew themselves transcribed all 305k of them; I’ll have to verify extra carefully to see. I believe nonetheless that the true bottleneck goes to be on the margins of getting the information and any DUAs that don’t can help you use an AI agent for evaluation, however I nonetheless consider we’ll see artistic methods the place researchers accommodate their DUAs to the letter however we nonetheless use AI brokers to hurry issues up. As an illustration, simply the creating of the audited code ex ante earlier than you enter some closed off location is itself alone going to be potential.
Past the substantive findings, this experiment taught me issues about utilizing LLMs for analysis:
-
The Batch API is underrated. Most researchers I do know use ChatGPT interactively. Possibly, they name the API one request at a time. However that’s an enormous possibly. Utilizing the Batch API is cheaper (50% off), handles giant jobs gracefully, and completed method quicker than promised. For those who’re doing any type of textual content evaluation at scale, study the Batch API. However you may also have Claude Code do it for you and clarify it to you in the best way your mind discovered alongside the best way.
-
Referee 2 was important. Having a separate Claude occasion overview the code caught actual bugs: edge instances in label normalization, lacking metrics (Cohen’s Kappa), considerations about immediate design. The code that ran was higher than the code I’d have submitted with out overview.
-
Not sticking to my deliberate workflow. However on the similar time, yesterday I inadvertently used referee 2 from inside the similar context window which as I stated violates the whole level of utilizing referee 2. We don’t need college students grading their very own exams. And we don’t need audits to be finished by the very Claude Code manifestation that wrote the code. So one way or the other there’s a psychological factor in regards to the referee 2 workflow that’s nonetheless not clicking for me, and I’m unsure what it’s. I don’t know if it’s as a result of I’m filming myself working, or what, however the level is, you received’t get an error if you audit your code utilizing referee2 from the wrong Claude Code context window. Which signifies that I can audit my code incorrectly and by no means know. I solely know as a result of a reader/viewer caught it and informed me, which has given me pause about how workflows will work now.
-
$11 will not be some huge cash. The fee barrier for this sort of analysis is now trivially low. The barrier is figuring out the best way to set it up—which is why I wrote this.
-
2.6 hours will not be a number of time. I anticipated to attend in a single day. I barely completed dinner. For those who’re iterating on immediate designs or testing totally different fashions, you possibly can run a number of experiments in a day.
Let me put the sensible numbers in a single place:
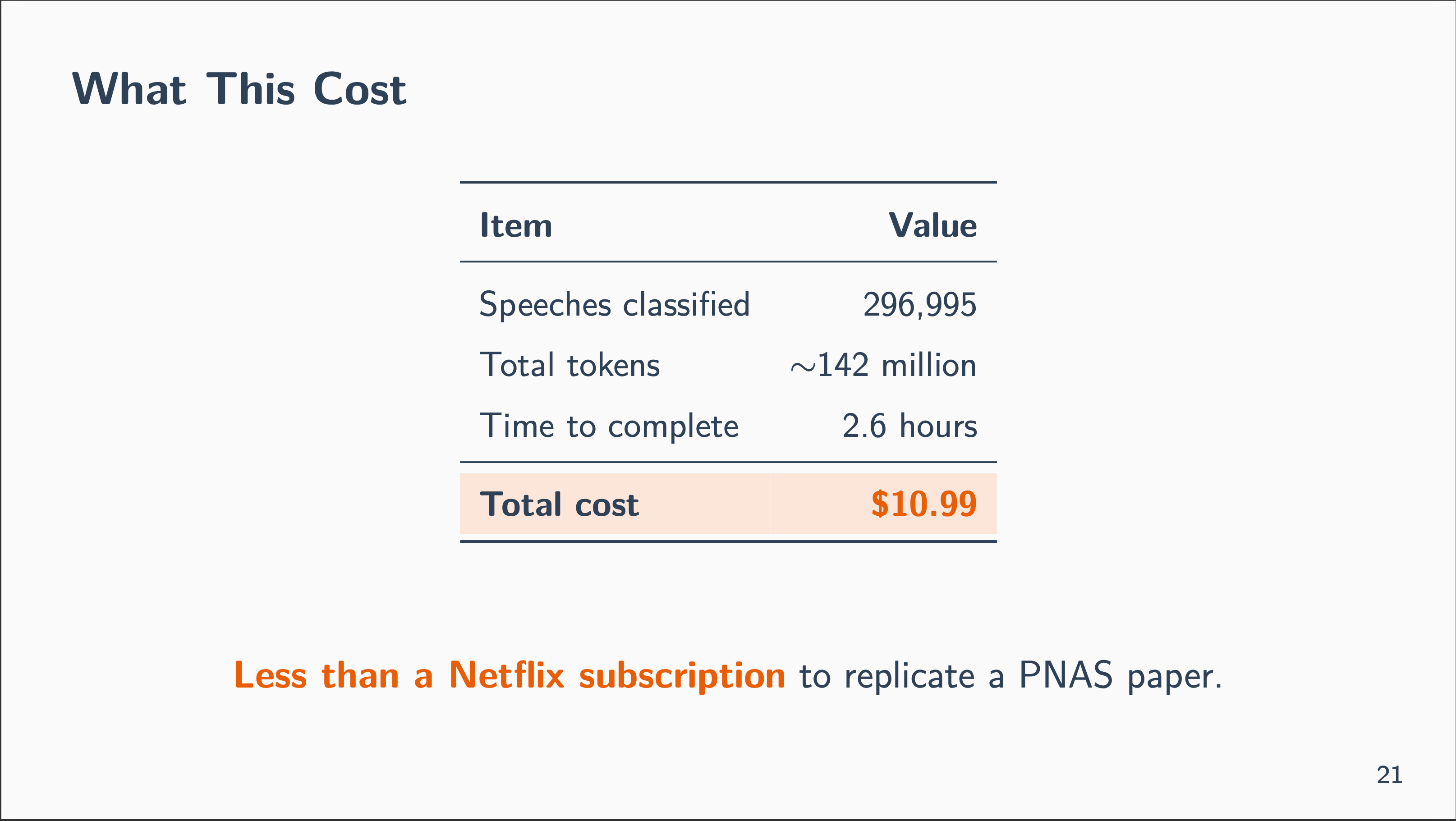
That catchphrase within the caption — Lower than a Netflix subscription to duplicate a PNAS paper — was Claude Code’s personal astonishment at this entire factor!
Three years in the past, in case you wished to categorise 300,000 textual content paperwork, you had two choices: rent human annotators (costly, gradual) or practice a customized NLP mannequin (requires experience, compute, labeled information).
Now there’s a 3rd possibility: ship your paperwork to a general-purpose LLM and get ends in just a few hours for pocket change. And use Claude Code (or Codex or one thing like them each) that will help you do it so that you don’t mess it up.
The outcomes received’t be equivalent to a fine-tuned mannequin, however that’s the purpose. It’s a unique NLP classification. This train wasn’t about making an attempt to talk into that, although. I actually didn’t know what I used to be going to seek out. I simply wished to indicate that Claude Code pulled all this collectively from the replication package deal it discovered itself on-line, set it up and submitted the batches to openai. All for less than $11 and round 4 1/2 hours time begin to end, together with making the cool decks to show me it. For a lot of analysis questions, that’s adequate for simply gaining fast and lasting insights.
This modifications who can do computational textual content evaluation. You don’t want a machine studying background. You don’t want GPU clusters. You don’t want a finances for annotation.
You want a analysis query, some textual content information, and eleven {dollars}.
Authentic paper:
Card, D., Chang, S., Becker, C., Mendelsohn, J., Voigt, R., Boustan, L., Abramitzky, R., & Jurafsky, D. (2022). Computational evaluation of 140 years of US political speeches reveals extra optimistic however more and more polarized framing of immigration. PNAS, 119(31), e2120510119.
Replication information:
github.com/dallascard/us-immigration-speeches
Our replication:
That is Half 2 of a two-part collection on utilizing LLMs for analysis replication. Half 1 lined the setup; this half lined the outcomes. For those who’re excited about making an attempt this your self, the important thing instruments are Claude Code for orchestration, the OpenAI Batch API for scale, and a wholesome dose of methodological skepticism.