

{kind=link}
The Amazon.com Catalog is the muse of each buyer’s buying expertise—the definitive supply of product info with attributes that energy search, suggestions, and discovery. When a vendor lists a brand new product, the catalog system should extract structured attributes—dimensions, supplies, compatibility, and technical specs—whereas producing content material equivalent to titles that match how prospects search. A title isn’t a easy enumeration like coloration or dimension; it should steadiness vendor intent, buyer search conduct, and discoverability. This complexity, multiplied by hundreds of thousands of every day submissions, makes catalog enrichment a really perfect proving floor for self-learning AI.
On this submit, we reveal how the Amazon Catalog Staff constructed a self-learning system that repeatedly improves accuracy whereas decreasing prices at scale utilizing Amazon Bedrock.
The problem
In generative AI deployment environments, enhancing mannequin efficiency requires fixed consideration. As a result of fashions course of hundreds of thousands of merchandise, they inevitably encounter edge circumstances, evolving terminology, and domain-specific patterns the place accuracy might degrade. The normal method—utilized scientists analyzing failures, updating prompts, testing adjustments, and redeploying—works however is resource-intensive and struggles to maintain tempo with real-world quantity and selection. The problem isn’t whether or not we will enhance these programs, however the best way to make enchancment scalable and computerized somewhat than depending on handbook intervention. At Amazon Catalog, we confronted this problem head-on. The tradeoffs appeared inconceivable: giant fashions would ship accuracy however wouldn’t scale effectively to our quantity, whereas smaller fashions struggled with the complicated, ambiguous circumstances the place sellers wanted probably the most assist.
Resolution overview
Our breakthrough got here from an unconventional experiment. As a substitute of selecting a single mannequin, we deployed a number of smaller fashions to course of the identical merchandise. When these fashions agreed on an attribute extraction, we might belief the consequence. However after they disagreed—whether or not from real ambiguity, lacking context, or one mannequin making an error—we found one thing profound. These disagreements weren’t all the time errors, however they had been nearly all the time indicators of complexity. This led us to design a self-learning system that reimagines how generative AI scales. A number of smaller fashions course of routine circumstances by consensus, invoking bigger fashions solely when disagreements happen. The bigger mannequin is carried out as a supervisor agent with entry to specialised instruments for deeper investigation and evaluation. However the supervisor doesn’t simply resolve disputes; it generates reusable learnings saved in a dynamic information base that helps stop total courses of future disagreements. We invoke extra highly effective fashions solely when the system detects excessive studying worth at inference time, whereas correcting the output. The result’s a self-learning system the place prices lower and high quality will increase—as a result of the system learns to deal with edge circumstances that beforehand triggered supervisor calls. Error charges fell repeatedly, not by retraining however by gathered learnings from resolved disagreements injected into smaller mannequin prompts. The next determine exhibits the structure of this self-learning system.
Within the self-learning structure, product knowledge flows by generator-evaluator employees, with disagreements routed to a supervisor for investigation. Put up-inference, the system additionally captures suggestions indicators from sellers (equivalent to itemizing updates and appeals) and prospects (equivalent to returns and destructive opinions). Learnings from the sources are saved in a hierarchical information base and injected again into employee prompts, making a steady enchancment loop.
The next describes a simplified reference structure that demonstrates how this self-learning sample could be carried out utilizing AWS companies. Whereas our manufacturing system has further complexity, this instance illustrates the core parts and knowledge flows.
This technique could be constructed with Amazon Bedrock, which offers the important infrastructure for multi-model architectures. The flexibility of Amazon Bedrock to entry various basis fashions permits groups to deploy smaller, environment friendly fashions like Amazon Nova Lite as employees and extra succesful fashions like Anthropic Claude Sonnet as supervisors—optimizing each price and efficiency. For even higher price effectivity at scale, groups can even deploy open supply small fashions on Amazon Elastic Compute Cloud (Amazon EC2) GPU cases, offering full management over employee mannequin choice and batch throughput optimization. For productionizing a supervisor agent with its specialised instruments and dynamic information base, Bedrock AgentCore offers the runtime scalability, reminiscence administration, and observability wanted to deploy self-learning programs reliably at scale.
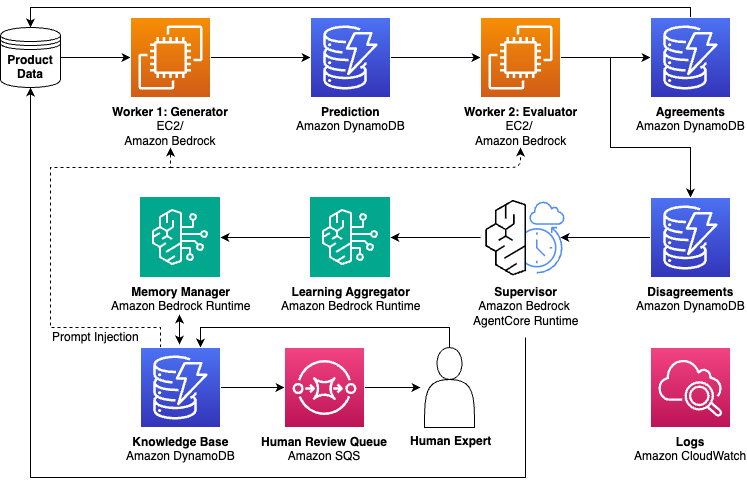
Our supervisor agent integrates with Amazon’s in depth Choice and Catalog Methods. The above diagram is a simplified view displaying the important thing options of the agent and among the AWS companies that make it attainable. Product knowledge flows by generator-evaluator employees (Amazon EC2 and Amazon Bedrock Runtime), with agreements saved straight and disagreements routed to a supervisor agent (Bedrock AgentCore). The educational aggregator and reminiscence supervisor make the most of Amazon DynamoDB for the information base, with learnings injected again into employee prompts. Human evaluation (Amazon Easy Queue Service (Amazon SQS)) and observability (Amazon CloudWatch) full the structure. Manufacturing implementations will doubtless require further parts for scale, reliability, and integration with current programs.
However how did we arrive at this structure? The important thing perception got here from an surprising place.
The perception: Turning disagreements into alternatives
Our perspective shifted throughout a debugging session. When a number of smaller fashions (equivalent to Nova Lite) disagreed on product attributes—decoding the identical specification in a different way based mostly on how they understood technical terminology—we initially noticed this as a failure. However the knowledge instructed a distinct story: merchandise the place our smaller fashions disagreed correlated with circumstances requiring extra handbook evaluation and clarification. When fashions disagreed, these had been exactly the merchandise that wanted further investigation. The disagreements had been surfacing studying alternatives, however we couldn’t have engineers and scientists deep-dive on each case. The supervisor agent does this mechanically at scale. And crucially, the purpose isn’t simply to find out which mannequin was proper—it’s to extract learnings that assist stop comparable disagreements sooner or later. That is the important thing to environment friendly scaling. Disagreements don’t simply come from AI employees at inference time. Put up-inference, sellers categorical disagreement by itemizing updates and appeals—indicators that our authentic extraction may need missed vital context. Clients disagree by returns and destructive opinions, typically indicating that product info didn’t match expectations. These post-inference human indicators feed into the identical studying pipeline, with the supervisor investigating patterns and producing learnings that assist stop comparable points throughout future merchandise. We discovered a candy spot: attributes with reasonable AI employee disagreement charges yielded the richest learnings—excessive sufficient to floor significant patterns, low sufficient to point solvable ambiguity. When disagreement charges are too low, they sometimes replicate noise or basic mannequin limitations somewhat than learnable patterns—for these, we think about using extra succesful employees. When disagreement charges are too excessive, it indicators that employee fashions or prompts aren’t but mature sufficient, triggering extreme supervisor calls that undermine the effectivity positive aspects of the structure. These thresholds will differ by activity and area; the bottom line is figuring out your personal candy spot the place disagreements signify real complexity price investigating, somewhat than basic gaps in employee functionality or random noise.
Deep dive: The way it works
On the coronary heart of our system are a number of light-weight employee fashions working in parallel—some as turbines extracting attributes, others as evaluators assessing these extractions. These employees could be carried out in a non-agentic manner with mounted inputs, making them batch-friendly and scalable. The generator-evaluator sample creates productive pressure, conceptually just like the productive pressure in generative adversarial networks (GANs), although our method operates at inference time by prompting somewhat than coaching. We explicitly immediate evaluators to be important, instructing them to scrutinize extractions for ambiguities, lacking context, or potential misinterpretations. This adversarial dynamic surfaces disagreements that signify real complexity somewhat than letting ambiguous circumstances cross by undetected. When the generator and evaluator agree, now we have excessive confidence within the consequence and course of it at minimal computational price. This consensus path handles most product attributes. After they disagree, we’ve recognized a case price investigating—triggering the supervisor to resolve the dispute and extract reusable learnings.
Our structure treats disagreement as a common studying sign. At inference time, worker-to-worker disagreements catch ambiguity. Put up-inference, vendor suggestions catches misalignments with intent and buyer suggestions catches misalignments with expectations. The three channels feed the supervisor, which extracts learnings that enhance accuracy throughout the board. When employees disagree, we invoke a supervisor agent—a extra succesful mannequin that resolves the dispute and investigates why it occurred. The supervisor determines what context or reasoning the employees lacked, and these insights turn out to be reusable learnings for future circumstances. For instance, when employees disagreed about utilization classification for a product based mostly on sure technical phrases, the supervisor investigated and clarified that these phrases alone had been inadequate—visible context and different indicators wanted to be thought of collectively. The supervisor generated a studying about the best way to correctly weight completely different indicators for that product class. This studying instantly up to date our information base, and when injected into employee prompts for comparable merchandise, helped stop future disagreements throughout 1000’s of things. Whereas the employees might theoretically be the identical mannequin because the supervisor, utilizing smaller fashions is essential for effectivity at scale. The architectural benefit emerges from this asymmetry: light-weight employees deal with routine circumstances by consensus, whereas the extra succesful supervisor is invoked solely when disagreements floor high-value studying alternatives. Because the system accumulates learnings and disagreement charges drop, supervisor calls naturally decline—effectivity positive aspects are baked straight into the structure. This worker-supervisor heterogeneity additionally permits richer investigation. As a result of supervisors are invoked selectively, they’ll afford to tug in further indicators—buyer opinions, return causes, vendor historical past—that may be impractical to retrieve for each product however present essential context when resolving complicated disagreements. When these indicators yield generalizable insights about how prospects need product info introduced—which attributes to spotlight, what terminology resonates, the best way to body specs—the ensuing learnings profit future inferences throughout comparable merchandise with out retrieving these resource-intensive indicators once more. Over time, this creates a suggestions loop: higher product info results in fewer returns and destructive opinions, which in flip displays improved buyer satisfaction.
The information base: Making learnings scalable
The supervisor investigates disagreements on the particular person product degree. With hundreds of thousands of things to course of, we’d like a scalable solution to remodel these product-specific insights into reusable learnings. Our aggregation technique adapts to context: high-volume patterns get synthesized into broader learnings, whereas distinctive or important circumstances are preserved individually. We use a hierarchical construction the place a big language mannequin (LLM)-based reminiscence supervisor navigates the information tree to position every studying. Ranging from the foundation, it traverses classes and subcategories, deciding at every degree whether or not to proceed down an current path, create a brand new department, merge with current information, or substitute outdated info. This dynamic group permits the information base to evolve with rising patterns whereas sustaining logical construction. Throughout inference, employees obtain related learnings of their prompts based mostly on product class, mechanically incorporating area information from previous disagreements. The information base additionally introduces traceability—when an extraction appears incorrect, we will pinpoint precisely which studying influenced it. This shifts auditing from an unscalable activity to a sensible one: as an alternative of reviewing a pattern of hundreds of thousands of outputs—the place human effort grows proportionally with scale—groups can audit the information base itself, which stays comparatively mounted in dimension no matter inference quantity. Area consultants can straight contribute by including or refining entries, no retraining required. A single well-crafted studying can instantly enhance accuracy throughout 1000’s of merchandise. The information base bridges human experience and AI functionality, the place automated learnings and human insights work collectively.
Classes realized and finest practices
When this self-learning structure works finest:
- Excessive-volume inference the place enter variety drives compounded studying
- High quality-critical functions the place consensus offers pure high quality assurance
- Evolving domains with new patterns and terminology continually rising
It’s much less appropriate for low-volume eventualities (inadequate disagreements for studying) or use circumstances with mounted, unchanging guidelines.
Essential success components:
- Defining disagreements: With a generator-evaluator pair, disagreement happens when the evaluator flags the extraction as needing enchancment. With a number of employees, scale thresholds accordingly. The bottom line is sustaining productive pressure between employees. If disagreement charges fall exterior the productive vary (too low or too excessive), think about extra succesful employees or refined prompts.
- Monitoring studying effectiveness: Disagreement charges should lower over time—that is your major well being metric. If charges keep flat, examine information retrieval, immediate injection, or evaluator criticality.
- Data group: Construction learnings hierarchically and preserve them actionable. Summary steerage doesn’t assist; particular, concrete learnings straight enhance future inferences.
Frequent pitfalls
- Specializing in price over intelligence: Value discount is a byproduct, not the purpose
- Rubber-stamp evaluators: Evaluators that merely approve generator outputs gained’t floor significant disagreements—immediate them to actively problem and critique extractions
- Poor studying extraction: Supervisors should determine generalizable patterns, not simply repair particular person circumstances
- Data rot: With out group, learnings turn out to be unsearchable and unusable
The important thing perception: deal with declining disagreement charges as your north star metric—they present the system is actually studying.
Deployment methods: Two approaches
- Study-then-deploy: Begin with primary prompts and let the system be taught aggressively in a pre-production setting. Area consultants then audit the information base—not particular person outputs—to verify realized patterns align with desired outcomes. When permitted, deploy with validated learnings. That is superb for brand new use circumstances the place you don’t but know what good seems like—disagreements assist uncover the correct patterns, and information base auditing permits you to form them earlier than manufacturing.
- Deploy-and-learn: Begin with refined prompts and good preliminary high quality, then repeatedly enhance by ongoing studying in manufacturing. This works finest for well-understood use circumstances the place you’ll be able to outline high quality upfront however nonetheless need to seize domain-specific nuances over time.
Each approaches use the identical structure—the selection relies on whether or not you’re exploring new territory or optimizing acquainted floor.
Conclusion
What began as an experiment in catalog enrichment revealed a basic reality: AI programs don’t must be frozen in time. By embracing disagreements as studying indicators somewhat than failures, we’ve constructed an structure that accumulates area information by precise utilization. We watched the system evolve from generic understanding to domain-specific experience. It realized industry-specific terminology. It found contextual guidelines that adjust throughout classes. It tailored to necessities no pre-trained mannequin would encounter—all with out retraining, by learnings saved in a information base and injected again into employee prompts. For groups operationalizing comparable architectures, Amazon Bedrock AgentCore presents purpose-built capabilities:
- AgentCore Runtime handles fast consensus choices for routine circumstances whereas supporting prolonged reasoning when supervisors examine complicated disagreements
- AgentCore Observability offers visibility into which learnings drive affect, serving to groups refine information propagation and keep reliability at scale
The implications lengthen past catalog administration. Excessive-volume AI functions may gain advantage from this course of—and the flexibility of Amazon Bedrock to entry various fashions makes this structure easy to implement. The important thing perception is that this: we’ve shifted from asking “which mannequin ought to we use?” to “how can we construct programs that be taught our particular patterns? “Whether or not you learn-then-deploy for brand new use circumstances or deploy-and-learn for established ones, the implementation is simple: begin with employees suited to your activity, select a supervisor, and let disagreements drive studying. With the correct structure, each inference can turn out to be a possibility to seize area information. That’s not simply scaling—that’s constructing institutional information into your AI programs.
Acknowledgement
This work wouldn’t have been attainable with out the contributions and assist from Ankur Datta (Senior Principal Utilized Scientist – chief of science in On a regular basis Necessities Shops), Zhu Cheng (Utilized Scientist), Xuan Tang (Software program Engineer), Mohammad Ghasemi (Utilized Scientist). We sincerely recognize the contributions in designs, implementations, quite a few fruitful brain-storming periods, and all of the insightful concepts and strategies.
In regards to the authors
 Tarik Arici is a Principal Scientist at Amazon Choice and Catalog Methods (ASCS), the place he pioneers self-learning generative AI programs design for catalog high quality enhancement at scale. His work focuses on constructing AI programs that mechanically accumulate area information by manufacturing utilization—studying from buyer opinions and returns, vendor suggestions, and mannequin disagreements to enhance high quality whereas decreasing prices. Tarik holds a PhD in Electrical and Pc Engineering from Georgia Institute of Expertise.
Tarik Arici is a Principal Scientist at Amazon Choice and Catalog Methods (ASCS), the place he pioneers self-learning generative AI programs design for catalog high quality enhancement at scale. His work focuses on constructing AI programs that mechanically accumulate area information by manufacturing utilization—studying from buyer opinions and returns, vendor suggestions, and mannequin disagreements to enhance high quality whereas decreasing prices. Tarik holds a PhD in Electrical and Pc Engineering from Georgia Institute of Expertise.
 Sameer Thombare is a Senior Product Supervisor at Amazon with over a decade of expertise in Product Administration, Class/P&L Administration throughout various industries, together with heavy engineering, telecommunications, finance, and eCommerce. Sameer is keen about growing repeatedly enhancing closed-loop programs and leads strategic initiatives inside Amazon Choice and Catalog Methods (ASCS) to construct a complicated self-learning closed-loop system that synthesize indicators from prospects, sellers, and provide chain operations to optimize outcomes. Sameer holds an MBA from the Indian Institute of Administration Bangalore and an engineering diploma from Mumbai College.
Sameer Thombare is a Senior Product Supervisor at Amazon with over a decade of expertise in Product Administration, Class/P&L Administration throughout various industries, together with heavy engineering, telecommunications, finance, and eCommerce. Sameer is keen about growing repeatedly enhancing closed-loop programs and leads strategic initiatives inside Amazon Choice and Catalog Methods (ASCS) to construct a complicated self-learning closed-loop system that synthesize indicators from prospects, sellers, and provide chain operations to optimize outcomes. Sameer holds an MBA from the Indian Institute of Administration Bangalore and an engineering diploma from Mumbai College.
 Amin Banitalebi acquired his PhD within the Digital Media on the College of British Columbia (UBC), Canada, in 2014. Since then, he has taken numerous utilized science roles spanning over areas in laptop imaginative and prescient, pure language processing, suggestion programs, classical machine studying, and generative AI. Amin has co-authored over 90 publications and patents. He’s at present an Utilized Science Supervisor in Amazon On a regular basis Necessities.
Amin Banitalebi acquired his PhD within the Digital Media on the College of British Columbia (UBC), Canada, in 2014. Since then, he has taken numerous utilized science roles spanning over areas in laptop imaginative and prescient, pure language processing, suggestion programs, classical machine studying, and generative AI. Amin has co-authored over 90 publications and patents. He’s at present an Utilized Science Supervisor in Amazon On a regular basis Necessities.
 Puneet Sahni is a Senior Principal Engineer at Amazon Choice and Catalog Methods (ASCS), the place he has spent over 8 years enhancing the completeness, consistency, and correctness of catalog knowledge. He focuses on catalog knowledge modeling and its software to enhancing Promoting Accomplice and buyer experiences, whereas utilizing ML/DL and LLM-based enrichment to drive enhancements in catalog knowledge high quality.
Puneet Sahni is a Senior Principal Engineer at Amazon Choice and Catalog Methods (ASCS), the place he has spent over 8 years enhancing the completeness, consistency, and correctness of catalog knowledge. He focuses on catalog knowledge modeling and its software to enhancing Promoting Accomplice and buyer experiences, whereas utilizing ML/DL and LLM-based enrichment to drive enhancements in catalog knowledge high quality.
 Erdinc Basci joined Amazon in 2015 and brings over 23 years of know-how {industry} expertise. At Amazon, he has led the evolution of Catalog system architectures—together with ingestion pipelines, prioritized processing, and site visitors shaping—in addition to catalog knowledge structure enhancements equivalent to segmented presents, product specs for manufacture-on-demand merchandise, and catalog knowledge experimentation. Erdinc has championed a hands-on efficiency engineering tradition throughout Amazon companies unlocking $1B+ annualized price financial savings and 20%+ latency wins throughout core Shops companies. He’s at present centered on enhancing generative AI software efficiency and GPU effectivity throughout Amazon. Erdinc holds a BS in Pc Science from Bilkent College, Turkey, and an MBA from Seattle College, US.
Erdinc Basci joined Amazon in 2015 and brings over 23 years of know-how {industry} expertise. At Amazon, he has led the evolution of Catalog system architectures—together with ingestion pipelines, prioritized processing, and site visitors shaping—in addition to catalog knowledge structure enhancements equivalent to segmented presents, product specs for manufacture-on-demand merchandise, and catalog knowledge experimentation. Erdinc has championed a hands-on efficiency engineering tradition throughout Amazon companies unlocking $1B+ annualized price financial savings and 20%+ latency wins throughout core Shops companies. He’s at present centered on enhancing generative AI software efficiency and GPU effectivity throughout Amazon. Erdinc holds a BS in Pc Science from Bilkent College, Turkey, and an MBA from Seattle College, US.
 Mey Meenakshisundaram is a Director in Amazon Choice and Catalog Methods, the place he leads progressive GenAI options to ascertain Amazon’s worldwide catalog because the best-in-class supply for product info. His crew pioneers superior machine studying strategies, together with multi-agent programs and huge language fashions, to mechanically enrich product attributes and enhance catalog high quality at scale. Excessive-quality product info within the catalog is important for delighting prospects find the correct merchandise, empowering promoting companions to checklist their merchandise successfully, and enabling Amazon operations to cut back handbook effort.
Mey Meenakshisundaram is a Director in Amazon Choice and Catalog Methods, the place he leads progressive GenAI options to ascertain Amazon’s worldwide catalog because the best-in-class supply for product info. His crew pioneers superior machine studying strategies, together with multi-agent programs and huge language fashions, to mechanically enrich product attributes and enhance catalog high quality at scale. Excessive-quality product info within the catalog is important for delighting prospects find the correct merchandise, empowering promoting companions to checklist their merchandise successfully, and enabling Amazon operations to cut back handbook effort.