

{kind=link}
Introduction
In a univariate autoregression, a stationary time-series variable (y_t) can usually be modeled as relying by itself lagged values:
start{align}
y_t = alpha_0 + alpha_1 y_{t-1} + alpha_2 y_{t-2} + dots
+ alpha_k y_{t-k} + varepsilon_t
finish{align}
When one analyzes a number of time sequence, the pure extension to the autoregressive mannequin is the vector autoregression, or VAR, through which a vector of variables is modeled as relying on their very own lags and on the lags of each different variable within the vector. A two-variable VAR with one lag appears like
start{align}
y_t &= alpha_{0} + alpha_{1} y_{t-1} + alpha_{2} x_{t-1}
+ varepsilon_{1t}
x_t &= beta_0 + beta_{1} y_{t-1} + beta_{2} x_{t-1}
+ varepsilon_{2t}
finish{align}
Utilized macroeconomists use fashions of this way to each describe macroeconomic knowledge and to carry out causal inference and supply coverage recommendation.
On this publish, I’ll estimate a three-variable VAR utilizing the U.S. unemployment price, the inflation price, and the nominal rate of interest. This VAR is just like these utilized in macroeconomics for financial coverage evaluation. I focus on fundamental points in estimation and postestimation. Information and do-files are offered on the finish. Extra background and theoretical particulars could be present in Ashish Rajbhandari’s [earlier post], which explored VAR estimation utilizing simulated knowledge.
Information and estimation
When writing down a VAR, one makes two fundamental model-selection decisions. First, one chooses which variables to incorporate within the VAR. This determination is usually motivated by the analysis query and guided by idea. Second, one chooses the lag size. Heuristics could also be used, similar to “embody one 12 months value of lags”, or there are formal lag-length choice standards accessible. As soon as the lag size has been decided, one could proceed to estimation; as soon as the parameters of the VAR have been estimated, one can carry out postestimation procedures to evaluate mannequin match.
I exploit quarterly observations on the U.S. unemployment price, price of client value inflation, and short-term nominal rate of interest from 1955 to 2005. The three sequence have been downloaded from the Federal Reserve Financial Database at https://fred.stlouisfed.org. Within the Stata output that follows, the inflation price is known as inflation, the unemployment price as unrate, and the rate of interest as ffr (federal funds price). Therefore, the VAR I’ll estimate is
start{align}
start{bmatrix}
{bf inflation}_t {bf unrate}_t {bf ffr}_t
finish{bmatrix}
=
{bf a_0}
+
{bf A_1}
start{bmatrix}
{bf inflation}_{t-1} {bf unrate}_{t-1} {bf ffr}_{t-1}
finish{bmatrix}
+
dots
+
{bf A_k}
start{bmatrix}
{bf inflation}_{t-k} {bf unrate}_{t-k} {bf ffr}_{t-k}
finish{bmatrix}
+
start{bmatrix}
varepsilon_{1,t} varepsilon_{2,t} varepsilon_{3,t}
finish{bmatrix}
finish{align}
({bf a_0}) is a vector of intercept phrases and every of ({bf A_1}) to ({bf A_k}) is a (3 occasions 3) matrix of coefficients. VARs with these variables, or shut analogues to them, are widespread in financial coverage evaluation.
The subsequent step is to resolve on a wise lag size. I exploit the varsoc command to run lag-order choice diagnostics.
. varsoc inflation unrate ffr, maxlag(8)
Choice-order standards
Pattern: 41 - 236 Variety of obs = 196
+---------------------------------------------------------------------------+
|lag | LL LR df p FPE AIC HQIC SBIC |
|----+----------------------------------------------------------------------|
| 0 | -1242.78 66.5778 12.712 12.7323 12.7622 |
| 1 | -433.701 1618.2 9 0.000 .018956 4.54796 4.62922 4.74867 |
| 2 | -366.662 134.08 9 0.000 .010485 3.95574 4.09793 4.30696* |
| 3 | -351.034 31.257 9 0.000 .009801 3.8881 4.09123 4.38985 |
| 4 | -337.734 26.6 9 0.002 .009383 3.84422 4.1083 4.4965 |
| 5 | -319.353 36.763 9 0.000 .008531 3.7485 4.07351 4.5513 |
| 6 | -296.967 44.77* 9 0.000 .007447* 3.61191* 3.99787* 4.56524 |
| 7 | -292.066 9.8034 9 0.367 .007773 3.65373 4.10063 4.75759 |
| 8 | -286.45 11.232 9 0.260 .008057 3.68826 4.1961 4.94265 |
+---------------------------------------------------------------------------+
Endogenous: inflation unrate ffr
Exogenous: _cons
varsoc shows the outcomes of a battery of lag-order choice exams. The small print of those exams could also be present in assist varsoc. Each the chance ratio take a look at and Akaike’s info criterion suggest six lags, which I exploit by way of the remainder of this publish.
With variables and lag size in hand, there are two objects to estimate: the coefficient matrices and the covariance matrix of the error phrases. Coefficients could be estimated by least squares, equation by equation. The covariance matrix of the errors could also be estimated from the pattern covariance matrix of the residuals. var performs each duties.
The desk of coefficients is displayed by default, and the covariance estimate of the error phrases could be discovered within the saved outcome e(Sigma):
. var inflation unrate ffr, lags(1/6) dfk small
Vector autoregression
Pattern: 39 - 236 Variety of obs = 198
Log chance = -298.8751 AIC = 3.594698
FPE = .0073199 HQIC = 3.97786
Det(Sigma_ml) = .0041085 SBIC = 4.541321
Equation Parms RMSE R-sq F P > F
----------------------------------------------------------------
inflation 19 .430015 0.9773 427.7745 0.0000
unrate 19 .252309 0.9719 343.796 0.0000
ffr 19 .795236 0.9481 181.8093 0.0000
----------------------------------------------------------------
------------------------------------------------------------------------------
| Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
inflation |
inflation |
L1. | 1.37357 .0741615 18.52 0.000 1.227227 1.519913
L2. | -.383699 .1172164 -3.27 0.001 -.6150029 -.1523952
L3. | .2219455 .1107262 2.00 0.047 .0034489 .440442
L4. | -.6102823 .1105383 -5.52 0.000 -.8284081 -.3921565
L5. | .6247347 .1158098 5.39 0.000 .3962065 .8532629
L6. | -.2352624 .0719141 -3.27 0.001 -.3771708 -.093354
|
unrate |
L1. | -.4638928 .1386526 -3.35 0.001 -.7374967 -.1902889
L2. | .6567903 .2370568 2.77 0.006 .1890049 1.124576
L3. | -.271786 .2472491 -1.10 0.273 -.759684 .2161119
L4. | -.4545188 .2473079 -1.84 0.068 -.9425328 .0334952
L5. | .6755548 .2387697 2.83 0.005 .2043893 1.14672
L6. | -.1905395 .136066 -1.40 0.163 -.4590393 .0779602
|
ffr |
L1. | .1135627 .0439648 2.58 0.011 .0268066 .2003187
L2. | -.1155366 .0607816 -1.90 0.059 -.2354774 .0044041
L3. | .0356931 .0628766 0.57 0.571 -.0883817 .1597678
L4. | -.0928074 .0620882 -1.49 0.137 -.2153263 .0297116
L5. | .0285487 .0605736 0.47 0.638 -.0909816 .1480789
L6. | .0309895 .0436299 0.71 0.478 -.0551055 .1170846
|
_cons | .3255765 .1730832 1.88 0.062 -.0159696 .6671226
-------------+----------------------------------------------------------------
unrate |
inflation |
L1. | .0903987 .0435139 2.08 0.039 .0045326 .1762649
L2. | -.1647856 .0687761 -2.40 0.018 -.3005019 -.0290693
L3. | .0502256 .064968 0.77 0.440 -.0779761 .1784273
L4. | .0919702 .0648577 1.42 0.158 -.036014 .2199543
L5. | -.0091229 .0679508 -0.13 0.893 -.1432106 .1249648
L6. | -.0475726 .0421952 -1.13 0.261 -.1308366 .0356914
|
unrate |
L1. | 1.511349 .0813537 18.58 0.000 1.350814 1.671885
L2. | -.5591657 .1390918 -4.02 0.000 -.8336363 -.2846951
L3. | -.0744788 .1450721 -0.51 0.608 -.3607503 .2117927
L4. | -.1116169 .1451066 -0.77 0.443 -.3979565 .1747227
L5. | .3628351 .1400968 2.59 0.010 .0863813 .639289
L6. | -.1895388 .079836 -2.37 0.019 -.3470796 -.031998
|
ffr |
L1. | -.022236 .0257961 -0.86 0.390 -.0731396 .0286677
L2. | .0623818 .0356633 1.75 0.082 -.0079928 .1327564
L3. | -.0355659 .0368925 -0.96 0.336 -.1083661 .0372343
L4. | .0184223 .0364299 0.51 0.614 -.0534651 .0903096
L5. | .0077111 .0355412 0.22 0.828 -.0624226 .0778449
L6. | -.0097089 .0255996 -0.38 0.705 -.0602247 .040807
|
_cons | .187617 .1015557 1.85 0.066 -.0127834 .3880173
-------------+----------------------------------------------------------------
ffr |
inflation |
L1. | .1425755 .1371485 1.04 0.300 -.1280603 .4132114
L2. | .1461452 .2167708 0.67 0.501 -.2816098 .5739003
L3. | -.0988776 .2047683 -0.48 0.630 -.502948 .3051928
L4. | -.4035444 .2044208 -1.97 0.050 -.8069291 -.0001598
L5. | .5118482 .2141696 2.39 0.018 .0892262 .9344702
L6. | -.1468158 .1329922 -1.10 0.271 -.40925 .1156184
|
unrate |
L1. | -1.411603 .2564132 -5.51 0.000 -1.917585 -.9056216
L2. | 1.525265 .4383941 3.48 0.001 .660179 2.39035
L3. | -.6439154 .4572429 -1.41 0.161 -1.546195 .2583646
L4. | .8175053 .4573517 1.79 0.076 -.0849893 1.72
L5. | -.344484 .4415619 -0.78 0.436 -1.21582 .5268524
L6. | .0366413 .2516297 0.15 0.884 -.459901 .5331835
|
ffr |
L1. | 1.003236 .0813051 12.34 0.000 .8427961 1.163676
L2. | -.4497879 .1124048 -4.00 0.000 -.6715968 -.2279789
L3. | .4273715 .1162791 3.68 0.000 .1979173 .6568256
L4. | -.0775962 .114821 -0.68 0.500 -.3041731 .1489807
L5. | .259904 .1120201 2.32 0.021 .0388542 .4809538
L6. | -.2866806 .0806857 -3.55 0.000 -.445898 -.1274631
|
_cons | .2580589 .3200865 0.81 0.421 -.3735695 .8896873
------------------------------------------------------------------------------
. matlist e(Sigma)
| inflation unrate ffr
-------------+---------------------------------
inflation | .1849129
unrate | -.0064425 .0636598
ffr | .0788766 -.09169 .6324
The output of var organizes its outcomes by equation, the place an “equation” is recognized with its dependent variable: therefore, there may be an inflation equation, an unemployment equation, and an rate of interest equation. e(Sigma) holds the covariance matrix of the estimated residuals from the VAR. Notice that the residuals are correlated throughout equations.
As you may anticipate, the desk of coefficients is fairly lengthy. Not together with the fixed phrases, a VAR with (n) variables and (okay) lags could have (kn^2) coefficients; our 3-variable, 6-lag VAR has almost 60 coefficients which are estimated with solely 198 observations. The choices dfk and small apply small-sample corrections to the large-sample statistics which are reported by default. We are able to look down the desk of coefficients, commonplace errors, t statistics, and p-values, however it’s not instantly informative to take a look at the coefficients on particular person covariates in isolation. Due to this, many utilized papers don’t even report the desk of coefficients; as a substitute, they report some postestimation statistics which are (hopefully) extra informative. The subsequent two sections will discover two widespread postestimation statistics which are used to evaluate VAR output: Granger causality exams and impulse–response features.
Evaluating the output of a VAR: Granger causality exams
A variable (x_t) is claimed to “Granger-cause” one other variable (y_t) if, given the lags of (y_t), the lags of (x_t) are collectively statistically vital within the (y_t) equation. For instance, the rate of interest Granger-causes unemployment if lags of the rate of interest are collectively statistically vital within the unemployment equation. The vargranger postestimation command performs a battery of Granger causality exams.
. quietly var inflation unrate ffr, lags(1/6) dfk small . vargranger Granger causality Wald exams +------------------------------------------------------------------------+ | Equation Excluded | F df df_r Prob > F | |--------------------------------------+---------------------------------| | inflation unrate | 3.5594 6 179 0.0024 | | inflation ffr | 1.6612 6 179 0.1330 | | inflation ALL | 4.6433 12 179 0.0000 | |--------------------------------------+---------------------------------| | unrate inflation | 2.0466 6 179 0.0618 | | unrate ffr | 1.2751 6 179 0.2709 | | unrate ALL | 3.3316 12 179 0.0002 | |--------------------------------------+---------------------------------| | ffr inflation | 3.6745 6 179 0.0018 | | ffr unrate | 7.7692 6 179 0.0000 | | ffr ALL | 5.1996 12 179 0.0000 | +------------------------------------------------------------------------+
As earlier than, equations are distinguished by their dependent variable. For every equation, vargranger exams for the Granger causality of every variable within the VAR individually, then exams for the Granger causality of all added variables collectively. Take into account the Granger causality exams for the unemployment equation. The row with “ffr excluded” exams the null speculation that each one coefficients on lags of the rate of interest within the unemployment equation are equal to zero, towards the choice that at the least one shouldn’t be equal to zero. The p-value of 0.27 doesn’t fall under the standard statistical significance threshold of 0.05; therefore, we can not reject the null speculation that lags of the rate of interest don’t have an effect on the unemployment price. With this mannequin and these knowledge, the rate of interest doesn’t Granger-cause unemployment. In contrast, within the rate of interest equation, lags of each inflation and unemployment are statistically vital and could be mentioned to Granger-cause the rate of interest.
The “all excluded” row for every equation excludes all lags that aren’t the autocorrelation coefficients in an equation; it’s a joint take a look at for the importance of all lags of all different variables in that equation. It could be thought-about a take a look at between a purely autoregressive specification (null) towards the VAR specification for that equation (alternate).
You’ll be able to replicate the outcomes of the Granger causality exams by operating bizarre least squares on every equation and utilizing take a look at with the suitable null speculation:
. quietly regress unrate l(1/6).unrate l(1/6).ffr l(1/6).inflation
. take a look at l1.inflation=l2.inflation=l3.inflation
> =l4.inflation=l5.inflation=l6.inflation=0
( 1) L.inflation - L2.inflation = 0
( 2) L.inflation - L3.inflation = 0
( 3) L.inflation - L4.inflation = 0
( 4) L.inflation - L5.inflation = 0
( 5) L.inflation - L6.inflation = 0
( 6) L.inflation = 0
F( 6, 179) = 2.05
Prob > F = 0.0618
. take a look at l1.ffr=l2.ffr=l3.ffr=l4.ffr=l5.ffr=l6.ffr=0
( 1) L.ffr - L2.ffr = 0
( 2) L.ffr - L3.ffr = 0
( 3) L.ffr - L4.ffr = 0
( 4) L.ffr - L5.ffr = 0
( 5) L.ffr - L6.ffr = 0
( 6) L.ffr = 0
F( 6, 179) = 1.28
Prob > F = 0.2709
The outcomes of a “handbook” Granger causality take a look at match the outcomes from vargranger.
Evaluating the output of a VAR: Impulse responses
The second set of statistics usually used to evaulate a VAR is to simulate some shocks to the system and hint out the results of these shocks on endogenous variables. However do not forget that the shocks have been correlated throughout equations,
. matlist e(Sigma)
| inflation unrate ffr
-------------+---------------------------------
inflation | .1849129
unrate | -.0064425 .0636598
ffr | .0788766 -.09169 .6324
and it’s ambiguous to speak a couple of “shock” to, say, the inflation equation when the error phrases are correlated throughout equations.
One method to this drawback is to suppose that there are underlying structural shocks (bf{u}_t), that are (by definition) uncorrelated, and that these shocks are associated to the reduced-form shocks by way of the next relationship:
start{align*}
boldsymbol{varepsilon}_t &= {bf A} {bf u}_t
E(bf{u}_t bf{u}_t’) &= bf{I}
finish{align*}
If we denote the covariance matrix of the error phrases by (boldsymbol{Sigma}), then the (bf{A}) matrix is linked to (boldsymbol{Sigma}) by way of
start{align*}
boldsymbol{Sigma} &= E(boldsymbol{varepsilon}_t
boldsymbol{ varepsilon}_t’)
&= E(bf{A} bf{u}_t bf{u}_t’ bf{A}’)
&= bf{A} E(bf{u}_t bf{u}_t’) bf{A}’
&= bf{A} bf{A}’
finish{align*}
As a result of we’ve estimated (boldsymbol{hat Sigma}), the issue is to assemble (bf{hat A}) from
start{align}
boldsymbol{hat Sigma} =bf{hat A} bf{hat A}’ label{cov} tag{1}
finish{align}
Many (bf{A}) matrices fulfill (1). One method to slender down the attainable candidates is to imagine that (bf{A}) is lower-triangular; then (bf{A}) could be discovered uniquely by way of a Cholesky decomposition of (bf{Sigma}). This method is so widespread that it’s constructed into the var postestimation outcomes and could be accessed straight.
The belief that (bf{A}) is lower-triangular imposes an ordering on the variables within the VAR, and totally different orderings will produce totally different (bf{A}). The financial content material of this ordering is that the shock to anybody equation impacts the variables later within the ordering contemporaneously however that every variable within the VAR is contemporaneously unaffected by the shocks to the equations above it. For this publish, I’ll impose the ordering we’ve used to date: the equations are ordered inflation first, then unemployment, then the rate of interest. The inflation shock is allowed to have an effect on all three variables contemporaneously; the unemployment shock is allowed to have an effect on the rate of interest contemporaneously, however not inflation; and the rate of interest shock comes “final” and doesn’t have an effect on both inflation or unemployment contemporaneously.
With (bf{A}) in hand, we are able to produce shocks which are uncorrelated throughout equations and hint out the results of these shocks on the variables within the VAR. We are able to construct the impulse–response features with irf create, then graph the output with irf graph.
. quietly var inflation unrate ffr, lags(1/6) dfk small . irf create var1, step(20) set(myirf) substitute (file myirf.irf now energetic) (file myirf.irf up to date) . irf graph oirf, impulse(inflation unrate ffr) response(inflation unrate ffr) > yline(0,lcolor(black)) xlabel(0(4)20) byopts(yrescale)
After operating the VAR, irf create creates an .irf file that shops quite a few outcomes from the VAR that could be of curiosity in postestimation. The outcomes of multiple VAR could also be saved in a single .irf file, so we give the VAR a reputation, on this case var1. The set() possibility names the .irf file—on this case myirf.irf—and units it because the “energetic” .irf file for the needs of later postestimation instructions. The step(20) possibility instructs irf create to generate sure statistics, similar to forecasts, out to a horizon of 20 durations.
The irf graph command graphs among the statistics saved within the .irf file. Of the various statistics in that file, we can be within the orthogonalized impulse–response perform, so we specify oirf, therefore, the command irf graph oirf. The impulse() and response() choices specify which equations to shock and which variables to graph; we are going to shock all equations and graph all variables.
The impulse–response graphs are the next:
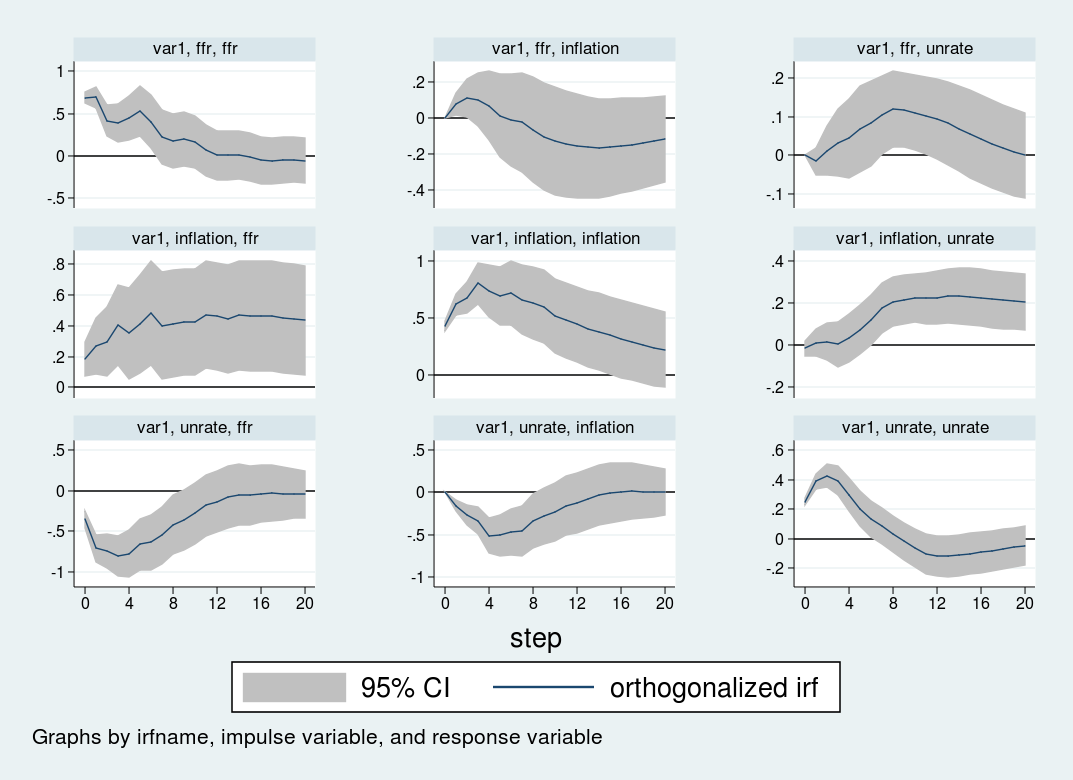{kind=link}
The impulse–response graph locations one impulse in every row and one response variable in every column. The horizontal axis for every graph is within the items of time that your VAR is estimated in, on this case quarters; therefore, the impulse–response graph exhibits the impact of a shock over a 20-quarter interval. The vertical axis is in items of the variables within the VAR; on this case, every thing is measured in proportion factors, so the vertical items in all panels are proportion level adjustments.
The primary row exhibits the impact of a one-standard-deviation impulse to the rate of interest equation. The rate of interest is persistent and stays elevated for about 12 durations (3 years) after the preliminary impulse. Inflation declines barely after eight quarters, however the response shouldn’t be statistically vital at any horizon. The unemployment price rises slowly for about 12 durations, peaking at a 0.2 perentage level improve, earlier than declining.
The second row exhibits the impression of a shock to the inflation equation. An sudden improve in inflation is related to a extremely persistent improve within the unemployment price and the rate of interest. Each the rate of interest and unemployment price stay elevated even 5 years after the impulse to inflation.
Lastly, the third row exhibits the impression to a shock to the unemployment equation. An impulse to the unemployment price causes inflation to say no by about one half of 1 proportion level over the next 12 months. The rate of interest responds strongly to the unemployment shock, falling by almost one proportion level over the 12 months following the shock.
Each the VAR and the ordering used listed here are illustrative. All of the inferences are conditional on the (bf{A}) matrix, that’s, the ordering of the variables within the VAR. Totally different orderings will produce totally different (bf{A}) matrices, which in flip will produce totally different impulse responses. As well as, there are identification methods that transcend merely ordering the equations; I’ll talk about these strategies in a later publish.
Conclusion
On this publish, I estimated a VAR mannequin and mentioned two widespread postestimation statistics: Granger causality exams and impulse–response features. In my subsequent publish, I’ll go deeper into the impulse response perform and describe different identification methods for performing structural inference in a VAR.